Find this useful? Share the visual.
{kind=link}
The Short Version
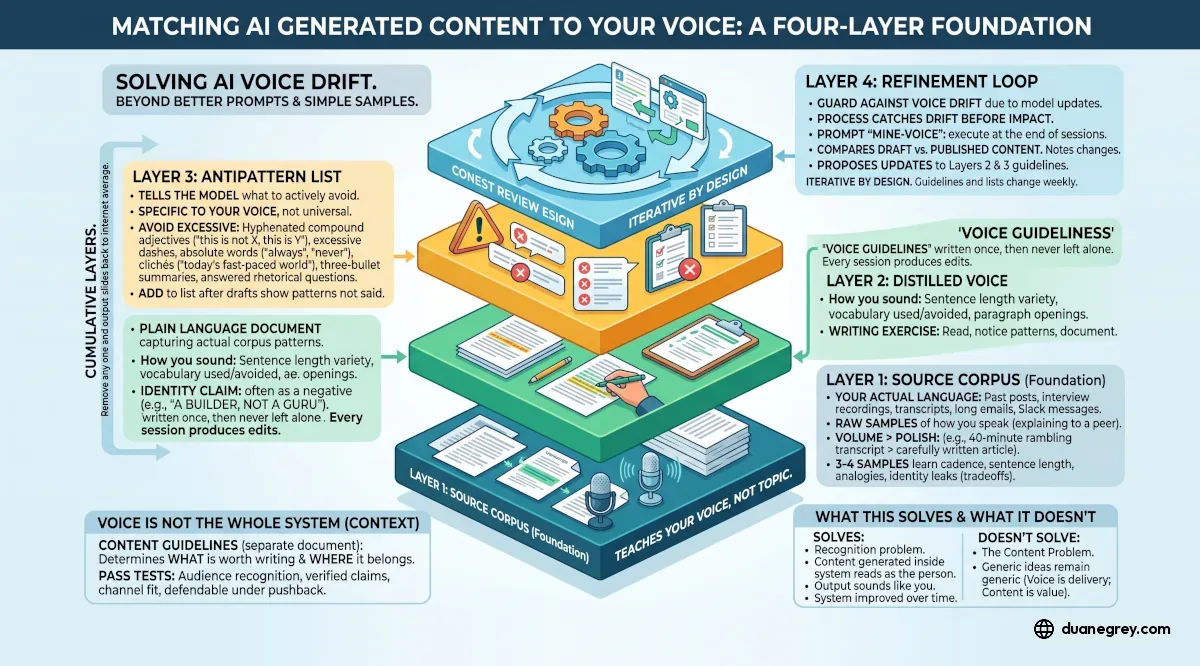
AI content without structure reads like the average AI output, with the same rhythm and rhetorical shapes repeating across posts. Matching AI to a human voice takes four layers that each do work the others cannot. A source corpus of how you speak. A distilled voice document. An antipattern list of AI tells. A refinement loop that catches drift session by session. Remove any one and the output slides back toward the internet's average.
There is a whole category of business now built around keeping executives visible on social media. The service interviews the executive once a month, transcribes the conversation, runs it through an AI and ships posts under their name. The service exists because the content generation problem is real. People do not have time to write, and being invisible on social media is a competitive liability.
The problem everyone is trying to solve is that AI content without structure reads like everyone else's output. The same rhythm and the same constructions repeat. The post goes up and the indicators of AI usage are obvious. The audience you want turns off. The people who would recognize your actual voice see the gap immediately.
Matching AI to a human voice is solvable. It is not solved by better prompts or by pasting two writing samples into ChatGPT and asking it to match the style. It takes a foundation with four distinct layers, each doing work the others cannot do.
Why One Layer Is Not Enough
A writing sample gives the model vocabulary and rhythm. It does not say what you refuse to say, what positions you hold, or what tells to avoid. A rules document names the tells, but without source material the output defaults to generic structure. A style guide without an example sounds like a style guide. An example without rules sounds like whoever was loudest in the training data.
The four layers are cumulative. Remove any one and the output slides back toward the average of the internet.
Layer 1: Source Corpus
The foundation is your actual language. Past posts, transcripts of calls, interview recordings, long emails, Slack messages you were willing to send. Raw samples of how you speak when you are explaining something to a peer.
Volume matters more than polish. A forty minute rambling transcript where you explain a real operational decision is more useful than a carefully written thought leadership article. The rambling version has the unguarded patterns. The polished version is already filtered through whoever edited it, including you.
A single sample is not enough. Three or four substantial ones give the model enough to learn cadence, sentence length distribution, the words you reach for when you are thinking out loud, the analogies you default to. One sample teaches the model your topic. Several teach it your voice.
The corpus is also where identity leaks through without being stated. A person who has run operations for twenty years writes about tradeoffs differently than someone who has read about operations for twenty years. That difference is not in any style guide. It is in the corpus, and the model will pick it up if you give it enough to work with.
Layer 2: Distilled Voice Characteristics
Raw corpus is not directly usable as a style prompt. It is too long, and the model will generalize in whatever direction it prefers unless you tell it what to pull from the samples.
This layer is a document in plain language that captures the patterns the corpus contains. It names what you sound like in one paragraph, how your sentences vary in length, the vocabulary you reach for and the vocabulary you avoid, how you open paragraphs, whether you use humor and what kind. The identity claim is often easier to state as a negative. A builder, not a guru. A practitioner, not a coach. A buyer, not a seller.
The distillation is a writing exercise. Read the corpus, notice the patterns, write them down. Do not underinvest in this because it looks like soft work. It is the part that decides whether the output sounds like the person.
I call mine the voice guidelines. It is written once and then rarely left alone. Content sessions produce edits.
Layer 3: Antipattern List
The first two layers tell the model what the voice is. The third tells the model what AI writing is, so it can actively avoid it.
Certain patterns are reliable tells. Hyphenated compound adjectives in prose. The "this is not X, this is Y" rhetorical structure. Em dashes used for emphasis. Absolute words like always, never, every, only. Phrases like "in today's fast paced world" or "the power of." Three bullet summaries at the end of every section. Rhetorical questions the writer immediately answers.
Each of these in isolation is fine, but concentration is the tell. An article with six hyphenated compounds and three "not X, this is Y" constructions reads as AI even if the ideas are original. Audiences cannot reliably name what is off. They recognize it and disengage.
The antipattern list is specific to the voice, not universal. A consultant who uses dashes heavily in their natural writing should not ban dashes. Start with ten or fifteen of the obvious tells. Add to it when a generated draft produces a phrase you would not say.
Layer 4: Refinement Loop
You need to guard against voice drifts. Model updates shift default output distributions. A voice system built in January on one model produces different output six months later, even with the same prompts. This layer is the process that catches drift before it impacts your content.
I run mine as a prompt I execute at the end of any content session, called /mine-voice. It compares the drafts the AI produced to what I published, writes down what changed and why, and proposes updates to Layer 2 and Layer 3. The output is a diff between the model's instinct and mine, formatted so I can fold it back in next session.
The loop is iterative by design. A single rewrite is noise. The same rewrite three sessions in a row is a rule. Drift does not stop, so the loop is ongoing. The voice guidelines and antipattern list change most weeks. That constant motion is how the system stays ahead of the models instead of behind them.
What The Output Looks Like
A real session summary, names removed:
Comments reviewed: 3 (governance rollout, AI code review, enterprise architecture) Rewrites observed: - Kept verbatim: the governance documentation line. Cut: the procurement expansion and the closing reframe. - Changed "keeps getting overlooked" to "keeps getting companies in trouble." Consequence language lands harder than observation language. - Changed "We added X" to "Adding X has helped." Gerund reads less corporate. - "every team" flagged and changed to "teams." Absolute words still slipping through. Voice refinements documented: 1. Name consequences over observations. 2. Stop or look forward in closers. Do not restate the body. 3. Never simplify the user's technical setup for narrative convenience. Pattern confirmed across recent sessions: Closing sentences get cut most often. The model's instinct is interpretive restatement. The voice wants a stop or a forward move.
The value is the last line. A single session would not have caught it. Three sessions with the same rewrite made it a rule. That rule is now in the antipattern list and the model stops producing interpretive closers.
Voice Is Not The Whole System
The four layers answer how the content should sound. They do not touch the other two questions any piece of content has to answer. What is worth writing, and where does it belong.
I keep those rules in a separate document, the content guidelines. It runs in front of the voice system, not inside it. Before a draft is written, the topic has to pass four tests. Would the specific person reading this recognize themselves in the scenario. Is the claim verified against what that audience does, or is it assumption dressed as fact. Does this belong on the channel it is being drafted for. Can the claims in it be defended under pushback.
A post that passes voice rules but fails content rules is a well written post nobody engages with. The voice made it sound like you. The topic made it irrelevant to the people listening.
The Same Voice Says Different Things In Different Rooms
Channel is where this matters most. What works on LinkedIn rarely transfers to Quora, and a blog post is a different thing again.
LinkedIn skews toward people inside existing companies, often larger ones. The concerns surfacing there are shaped by that context. Budget cycles, internal approval chains, vendor evaluations, governance, what a team of ten is doing differently than a team of two. A post framed around enterprise or midmarket realities finds its audience. A post framed around "what should I try as a solo operator" may not match this audience.
Quora skews the other direction. Individuals, small businesses, people evaluating a tool or approach for the first time. The reader is often earlier in the decision and wants the structure laid out. Frameworks, tutorials, depth on the basics. A Quora answer that assumes enterprise context may also not match this audience.
Neither audience is better or more sophisticated than the other. They are in different positions relative to the problem. The same voice can serve both, but the framing, the examples, and the implicit stakes change based on who is reading.
A blog post on your own site, optimized for search and AI citation, is a third thing. Structured, long, citation heavy, stat heavy, written to be found and quoted out of context. That is the piece you write when you want it to still be useful in six months or to show up in an AI assistant's answer to a question three years from now.
The voice stays the same across all three. The depth, the opening, the stat density, the closing, and the implicit question the reader is asking change with the channel. A voice system without a channel system produces content that sounds like you but reaches the wrong audience.
How To Build This In Practice
For a solo operator, the four layers collapse into roughly ten hours of upfront work.
Gather as much content as you can that represents how you should sound. It can be a blog post, a transcribed call with permission or voice memo, social media posts or email. That is Layer 1.
Review the collection of content. Note the phrases that recur, the sentence structures you prefer, the vocabulary you reach for. Write a one page document that names these patterns. That is Layer 2.
Generate three sample posts using just Layer 1 and Layer 2 as prompt context. Read them with fresh eyes. Note phrases that a peer would flag as "you would not say this." Make a list. That is Layer 3.
Put the three documents in a prompt template. Run the refinement prompt at the end of each content session. Fold the output back into Layer 2 and Layer 3 the same week. That is Layer 4.
What This Solves And What It Does Not
A four layer voice foundation solves the recognition problem. Content generated inside this system reads as the person who signed it. Your output sounds like you, but the more important result is that the system improves over time. Your post will feel like a consistent person thinking in public.
It does not solve the content problem. If the underlying ideas are generic, matching the voice just makes the generic output sound more like you. Voice is the delivery layer. Content guidelines and channel fit are what decide whether the delivery has anything worth carrying.
The test of a working voice system is simple. Print six months of posts, remove the name, and hand them to someone who knows the person professionally. If they can identify the author by voice alone, the system is working. If they cannot, something in the four layers is broken.
By the Numbers
75% of B2B decision makers and C-suite executives say a piece of thought leadership has led them to research a product or service they were not previously considering
2024 Edelman-LinkedIn B2B Thought Leadership Impact Report
Readers identified AI generated text in 70% of decision rounds; stylistic features like redundancy, repetition, and coherence drove detection more than content errors
Do humans identify AI-generated text better than machines? Evidence based on excerpts from German theses, ScienceDirect, 2025
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.