Find this useful? Share the visual.
{kind=link}
The Short Version
Check your server logs. AI answer engines identify themselves in the User-Agent header when they crawl your site. ClaudeBot, GPTBot, Amazonbot, PerplexityBot, and Meta-ExternalAgent leave fingerprints in the access log that most people do not read. A ten day window on my own site showed 2,328 bot hits from 21 different crawlers. If the data you need to evaluate your content strategy lives on properties you control, then the property you control has to be the primary publishing destination.
Check your server logs. AI answer engines identify themselves in the User-Agent header when they crawl your site, and that data is sitting in your NGINX or Apache access log right now. Most people don't know because platform analytics don't show it, and raw logs tend to get read when something breaks and not much else.
The Gap Between What You Publish and What You Can Measure
If you publish on LinkedIn, X, Medium, or Substack, your visibility into AI consumption of that content is close to nothing. Platform analytics were built to report impressions, engagements, and follower growth for humans. They don't surface which AI systems pulled a post into an index or used it to answer someone's question. That isn't a feature the platforms are holding back. It's a category of data they don't capture in a form they share back with creators.
The place that data exists in a form you can analyze is on a domain you control. When ClaudeBot, GPTBot, Amazonbot, PerplexityBot, or Meta-ExternalAgent hits one of your pages, your web server writes a line to the access log with the bot's identifier in the User-Agent field. That line is the evidence. Everything downstream, whether dashboards, reports, or trend graphs, is a different way of reading those log lines.
What This Looks Like
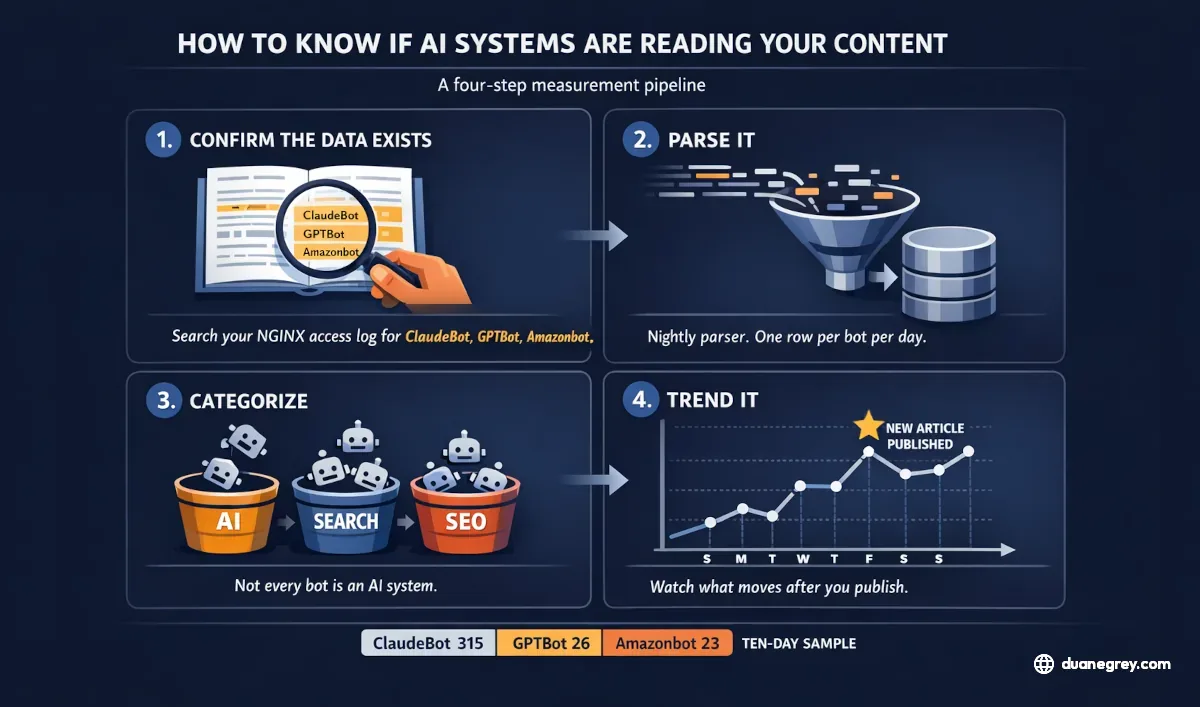
I run this on my own site. Across a recent ten day window, I logged 2,328 bot hits from 21 different crawlers. ClaudeBot accounted for 315 of them, with Claude-SearchBot adding another 35. GPTBot was at 26, Amazonbot at 23, Meta-ExternalAgent at 14, and Bytespider at 13. The rest were spread across traditional search crawlers, SEO tools, monitoring services, and the occasional scanner.
None of that showed up in any platform dashboard. It existed in the NGINX access log, which I was not reading until I built something that did.
The ClaudeBot number matters because Anthropic documents it as the crawler they use to gather web content. Claude-SearchBot is the one that fetches pages when Claude's search tool is looking up something for a user. GPTBot plays a similar role for OpenAI. Amazonbot feeds a set of Amazon services including Alexa. Each of those crawlers is evidence that a specific AI company has my content in its retrieval path.
Why This Changes Where You Publish
The strategic consequence is larger than "track your bots." If the data you need to evaluate your content strategy lives on properties you control, then the property you control has to be the primary publishing destination. Platforms become distribution, not origination.
I used to treat LinkedIn as the main channel and my own site as a secondary home for anything longer. Once the bot crawl data was in a daily report where I couldn't ignore it, the order flipped. The site is where the thing gets written. LinkedIn, Quora, and other platforms repost or link back. If I can't measure whether an AI system consumed a piece, I treat that placement as reach, not as something I can track.
Princeton researchers studying AI citation patterns found that structured content with statistics and citations gets cited 30-40% more often by AI systems than content without. That's a measurable effect, but the measurement depends on having pages you can tag, compare, and watch over time. A platform post gives you none of those levers.
How to Start Measuring This Yourself
You don't need a sophisticated pipeline to begin. The progression looks like this.
Confirm the data exists. Open your web server's access log. On NGINX, that's usually `/var/log/nginx/access.log`. Search for known bot identifiers: `ClaudeBot`, `GPTBot`, `Amazonbot`, `PerplexityBot`, `Meta-ExternalAgent`, `Bytespider`, `Googlebot`. If you see lines matching those strings, you already have the raw material. If you don't, check whether your CDN or hosting provider filters bots before requests reach your origin, or whether your log format captures the User-Agent field at all.
Parse it into something queryable. A single grep tells you what's there today. A nightly parser tells you what's changing. The goal is to turn log lines into rows in a database. One row per bot, per day, per category. From there you can track the trend across seven days, compare this week to last, and see what happens to the numbers after you publish something new.
Categorize the bots. Not every crawler is an AI system. Googlebot is search, Bytespider is TikTok's crawler, AhrefsBot and SemrushBot are SEO tools, and monitoring services like UptimeRobot show up too. Group them so you can look at "AI systems" as a distinct category and not have the AI traffic buried under routine search indexing or SEO tooling.
Watch for change after publishing. The useful question isn't "how many bot visits did I get yesterday." It's "did the number move after I published a new structured article with citations." That comparison is where the data starts to earn its place. If you publish something and crawl on that page stays flat for two weeks, the content isn't being picked up. If it rises within days, the structure worked.
What to Do With the Data
Bot crawl data tells you which AI systems are paying attention to your domain. It doesn't tell you whether those systems are citing you in answers. That second question, attribution in actual AI responses, is a harder problem. It requires querying the AI systems directly with prompts related to your topics and checking whether your site gets mentioned by name.
Crawl is the floor, though. If ClaudeBot isn't visiting your pages, Claude has nothing of yours to cite. If GPTBot isn't visiting your pages, ChatGPT has nothing of yours to cite. Everything else in a GEO strategy, whether structured content, schema markup, citation density, or topical depth, is aimed at converting crawl into retrieval and retrieval into citation. You can't work on that stack if you can't measure the bottom layer.
The Practical Takeaway
AI systems are reading content from the open web right now, and they identify themselves when they do it. The data isn't hidden. It's sitting in server logs that few people read. Parse it once, get it into a form where you can see trends, and you'll know which AI systems are paying attention to what you publish. You'll also learn, by their absence, which platforms you're pouring work into without any way to measure whether it mattered.
Publish on a domain you own and the answer to the question in the title is a grep command away. Publish elsewhere and you're trusting platforms that weren't built to tell you.
By the Numbers
Automated traffic accounted for 49.6% of all internet traffic in 2023, with a growing share attributable to AI-focused crawlers.
Imperva Bad Bot Report, 2024
Content optimized with citations, quotations, and statistics showed 30-40% higher visibility in generative engine responses.
Aggarwal et al., Generative Engine Optimization (GEO), Princeton University, 2024
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.