Find this useful? Share the visual.
{kind=link}
The Short Version
Analytics and AI agents consume data in different ways. Data that produces accurate dashboards can produce unreliable agents, and most organizations do not discover this until the agent is already built. Agents need completeness, relational context, consistency across systems, granularity, freshness, and reasoning over unstructured content. Analytics rarely required any of that because a human was usually in the loop. Build evaluation sets with subject matter experts and score the agent against them. The failures will reveal data problems your dashboards did not surface.
Because analytics and AI agents consume data in different ways. Data that produces accurate dashboards can produce unreliable agents, and most organizations don't discover this until the system is already built.
The Gap Most Teams Miss
Traditional analytics infrastructure, whether it's a star schema in a warehouse or raw files in a data lake, was built with a human somewhere in the loop. A warehouse organizes around known business questions. The lake keeps things flexible for exploration. In both cases, a person is interpreting results, noticing when something looks off, and adjusting their query or their conclusions accordingly.
AI agents don't have that judgment. An agent reasoning over customer data hits a missing field and either invents an answer or fails silently. There's no analyst squinting at a result and thinking "that doesn't look right, let me check the source." The system acts on what it finds, and what it finds is whatever the data says, gaps included.
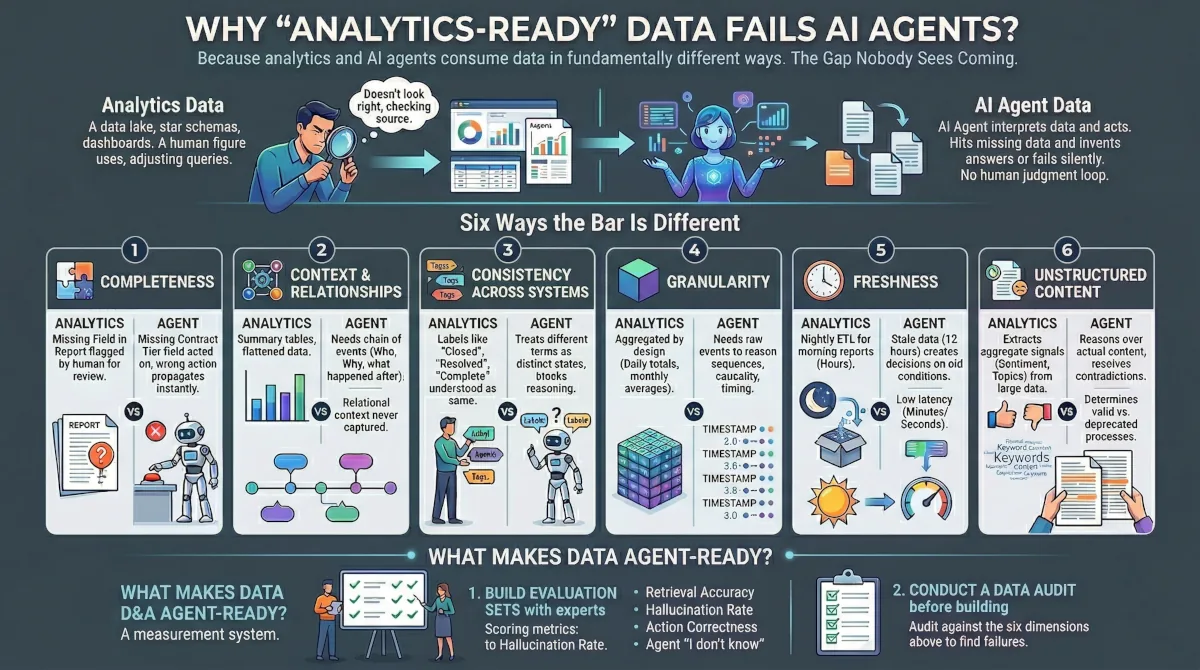
Six Ways the Bar Is Different
Completeness. Analytics has well established ways to handle missing records. Regulated industries like healthcare and finance enforce strict reconciliation. Even in less regulated environments, a gap in a report gets noticed and investigated by a human. An agent making a decision in real time has no reconciliation step. A missing contract tier field doesn't get flagged for review. It gets acted on, and the wrong action propagates before anyone knows it happened.
Context and relationships. Analytics data is often flattened into summary tables. An agent needs the chain of events. "This ticket was escalated" means nothing without knowing why, by whom, and what happened after. The relational context rarely gets captured because dashboards don't need it.
Consistency across systems. "Closed", "Resolved", and "Complete" mean the same thing to a person reading a report. An agent treats them as three distinct states. Multiply that across many fields labeled differently in many systems, and the agent's reasoning breaks down on terminology alone.
Granularity. Analytics aggregates by design. Daily totals, monthly averages, quarterly trends. Agents often need the raw events to reason about sequences, timing, and causality. A support agent trying to understand an escalation pattern can't work from weekly averages.
Freshness. A nightly ETL feeding a morning report is fine for analytics. An agent acting on data that's 12 hours stale makes decisions based on conditions that no longer exist. The tolerance for latency drops from hours to minutes or seconds.
Unstructured content. Analytics has been extracting value from free text for years: sentiment scores from support tickets, topic clusters from surveys, keyword trends from call transcripts. But that work pulls a structured summary out of unstructured input. A sentiment model trained on 10,000 support tickets doesn't care if 50 of them reference a deprecated process. An agent answering a specific question using one of those 50 records gives a wrong answer. Agents need to read the underlying text, resolve contradictions between documents, and know whether a runbook was written for the current system or one that was replaced six months ago. That's a different quality bar than aggregate extraction.
How Teams Discover This
A team builds an agent prototype using existing data. Early demos look promising because the test cases are clean. Then rigorous evaluation begins, with queries and edge cases drawn from production traffic.
The eval results expose specific failures. The agent gets escalation routing wrong 34% of the time because resolution notes are unstructured free text. It contradicts itself on contract terms because three systems store overlapping but inconsistent records. It confidently answers questions using information from a deprecated runbook.
Each failure traces back to a data quality problem that dashboards had no reason to surface, because dashboards don't reason about individual records with full context.
What Makes Data Ready for Agents
The fix isn't a single cleanup pass. It's a measurement system.
Build evaluation sets with subject matter experts who know what correct looks like for your specific workflows. Run the agent against those evals and score it by retrieval accuracy, hallucination rate, action correctness, and whether the agent appropriately says "I don't know" when it should.
Failures in the eval will reveal fixable data problems. Missing data relationships will need to get connected, inconsistent terminology should be normalized and stale content gets flagged or removed. Then you run the evals again and measure whether the score improved.
This turns "our data isn't ready" from an ambiguous blocker into an engineering problem with a measurable path forward. The eval suite becomes the shared source of truth between the team building the agent and the team that owns the data.
The Practical Takeaway
If your organization has invested in analytics infrastructure, you're ahead of companies starting from nothing. But the gap between data that serves analytics and data that serves agents is real, and it's larger than most teams expect.
Before building an agent, audit your data against the six dimensions above. The ones that fail are where the system will fail. Knowing that before you start building saves months of debugging symptoms that trace back to data problems that existed before the first line of code was written.
By the Numbers
Less than 20% of organizations report having mature data readiness for AI, increasing the risk of agent failure, hallucination, or unintended actions in production
Digital Applied, AI Agent Scaling Gap Report, March 2026
78% of enterprises have AI agent pilots but only 14% have successfully scaled an agent to organization-wide operational use
Digital Applied, Agentic AI Statistics 2026 Collection
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.