Why can a predictive model look perfect on paper and still be worthless?
Find this useful? Share the visual.
{kind=link}
The Short Version
A model can score well on any metric you care about and still have learned nothing useful. The default time series evaluation (train on the past, test on the future) catches one kind of data leakage and misses another. If the same entity appears in both training and test sets, static features let the model cheat by memorizing rather than generalizing. The fix is a leave one entity out evaluation alongside the walk forward one. If the two scores agree, the model has learned something transferable. If they disagree, you know the apparent skill was inflated and by how much.
A model can score well on any metric you care about and still have learned nothing useful. It takes a specific kind of check to catch the failure, and the default evaluation most tutorials teach will not catch it.
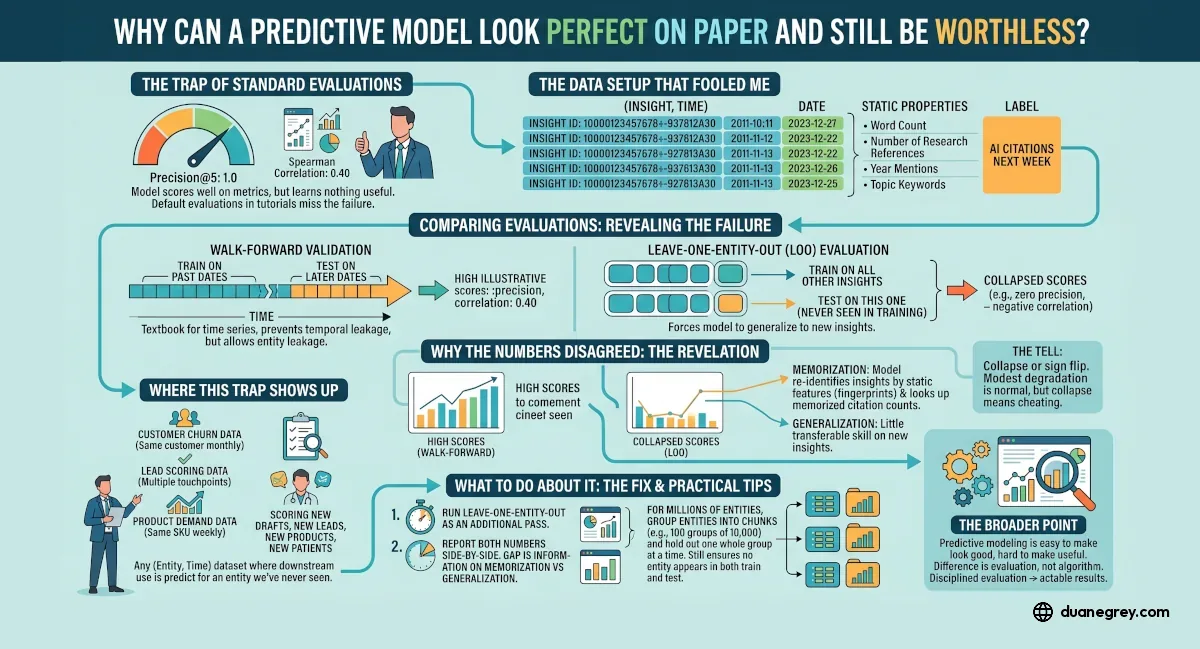
I ran into this last week on my own project. I was trying to predict which of my published insights would get cited by AI assistants like ChatGPT and Perplexity. I trained a reasonable model, ran the standard evaluation, and got a top five precision of 1.0. That metric, precision@5, asks a simple question. Take the five items the model ranked highest, and of those five, how many were positives? A score of 1.0 means five out of five. Each insight the model ranked in its top five was in fact cited. If I had stopped there, I would have shipped a scoring tool that tells you very little about future drafts.
Here is how I caught it, and how you can catch the same failure in your own work.
The Setup That Fooled Me
My dataset has one row per insight per observation day. An insight published in March shows up once on March 15, once on March 16, and so on. Hundreds of rows for the same insight over time. The label on each row is how many AI citations that insight received in the following week.
The textbook evaluation for time series data is walk forward validation. You train on rows from earlier dates, test on rows from later dates. It respects the arrow of time, and it is the right instinct. Under that evaluation my model got a Spearman correlation of 0.40 and a precision@5 of 1.0. Spearman correlation measures whether a model's ranking of items lines up with the real ranking. It runs from negative one (the model ranks things in exactly the wrong order) through zero (no relationship) to positive one (the model ranks things in exactly the right order). A score of 0.40 on sparse data is a respectable outcome. Combined with a perfect top five, it looked like a working model.
Those numbers felt wrong. They were better than the recency baseline by a wide margin, and recency was already eating most of what was explainable. Something was off.
The Check That Revealed the Problem
Walk forward validation tests whether the model can predict the future for insights it already knows. That is a legitimate question, but it was not my question. I was building a tool to score new drafts, not yesterday's insights. The right question is whether the model can predict citations for an insight it has not seen before.
The evaluation that answers that question is leave one entity out. For each insight in the dataset, you train on the rest and test on this one. Then you pool the results across the folds. The model does not see the target insight in training, so it has to generalize.
I ran it. The same model that scored 0.40 correlation and 1.0 precision under walk forward collapsed to a negative correlation and zero hits in the top five under leave one out. A sign flip on correlation. The best model I could fit had very little generalizable skill on new insights at all.
Why the Two Numbers Disagreed
The model was memorizing, not learning. Each insight has dozens of static properties that do not change across its rows. Word count, number of research references, year mentions in the body, topic keywords. When the model saw the same insight at a later date during walk forward training, it had already seen that insight's feature fingerprint during training on earlier dates. It learned to re-identify insights by their unique signature, then looked up the citation count it had already memorized for them.
This is not a bug in any particular algorithm. It is a structural problem with how the data was split. "Train on the past, test on the future" prevents one kind of leakage, the temporal kind, and does nothing about the other kind. If the same entity appears in both the training set and the test set, static features let the model cheat.
The tell is clear when you look for it. A model that has learned something shows modest degradation between the two evaluations. A walk forward score of 0.75 might drop to 0.72 under leave one out. Collapse toward zero, or a sign flip, means memorization was doing the work.
Where This Trap Shows Up
Any dataset shaped as rows of (entity, time) is exposed. That covers a lot of business data.
Customer churn data where the same customer appears each month. Lead scoring data where the same lead has multiple touchpoints. Product demand data where the same SKU appears each week. Any scoring application for new drafts, new leads, new products, new patients.
If the downstream use is "predict for an entity we already know," walk forward is the honest evaluation. If the downstream use is "predict for an entity we have not seen before," leave one entity out is the honest evaluation. A lot of real applications are the second case dressed up as the first.
What To Do About It
The fix is a single additional evaluation pass. Before trusting a strong number on data with repeated entities, run leave one entity out and report both side by side. If they agree, the model has learned something transferable. If they disagree, you know the walk forward number was inflated and you know by how much.
Two practical notes from running this. Leave one out gets slow when you have a lot of entities, because you have to train the model from scratch once for each entity. For a few dozen, it finishes in seconds. For millions of customers or products, running it that way is not realistic. The fix is to group your entities into chunks, say a hundred groups of ten thousand, and hold out one whole group at a time instead of one entity at a time. You still do not let an entity appear in both training and testing, which is the part that matters. You just do it a hundred times instead of a million.
Reporting both numbers is the right move even when they agree. The gap between them is itself information. It quantifies how much of your apparent skill is memorization versus generalization.
The Broader Point
Predictive modeling is easy to make look good and hard to make useful. The difference is almost always in the evaluation, not the algorithm. A sophisticated model with a sloppy evaluation produces confident nonsense. A simple model with a disciplined evaluation produces something you can act on.
I plan to keep writing about this project as the data grows. This piece is the methodology post, the lesson I would have wanted before I started. Later installments will cover what the features reveal about AI citation behavior once there is enough data to make claims. For now, if you are scoring entities that will be new at prediction time, leave one out is not optional.
By the Numbers
Tree-based models with more features than the square root of the training sample size tend to memorize rather than generalize, requiring careful feature selection on small datasets.
Hastie, Tibshirani, and Friedman, The Elements of Statistical Learning, 2nd ed., 2009
Cross-validation schemes that ignore group structure in the data produce systematically optimistic performance estimates; grouped and leave-one-group-out schemes are recommended for repeated-measures data.
Roberts et al., 'Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure,' Ecography, 2017
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.