Find this useful? Share the visual.
{kind=link}
The Short Version
When a chat model changes, you notice. The output reads differently and someone on the team says it does not feel right. When an embedding model changes, you do not notice. Old vectors stay where they were stored. New vectors fall in slightly different positions. The retrieval system keeps returning results, just less relevant ones. Pin model versions explicitly and record the exact version with each embedding you store, so you can audit which vectors came from which model. Treat any model upgrade as a re-embedding migration across your document collection, not a transparent swap.
When a chat model changes, you notice. The output reads differently and someone says it does not feel right. Embedding model changes leave no such trace.
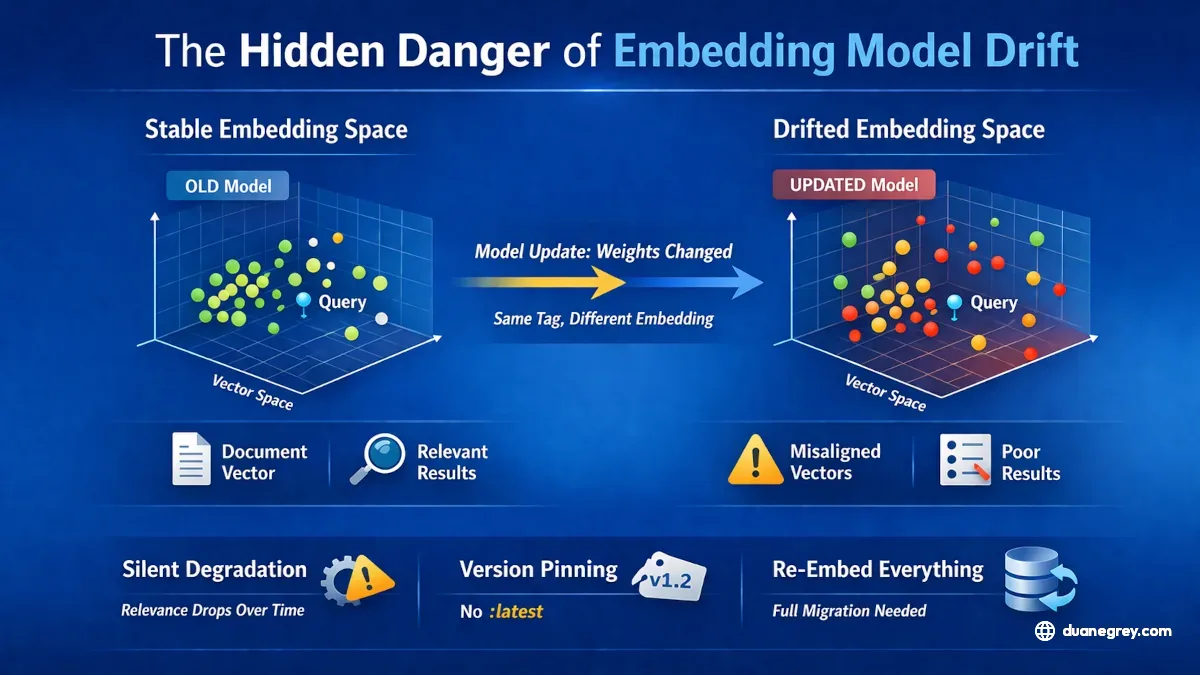
An embedding model converts text into a vector, a list of numbers that represents the meaning of that text in a geometric space. Your retrieval system (RAG, semantic search, recommendation engine) works by comparing those vectors. Documents embedded last month sit in the database alongside documents embedded today, on the assumption they live in the same geometric space.
When the model provider updates the weights behind the same tag, the geometry changes and new vectors land in slightly different positions. The old vectors cannot move. They are already stored.
Retrieval quality slowly degrades. The query vector and the document vectors were computed by different versions of the same model, so cosine similarity scores drift. Items that should rank first start appearing third or fifth. The system still returns answers and still looks functional. Nothing throws an error.
Chat changes show up in the output. Embedding changes do not. You find out weeks later when someone notices search results feel less relevant, or you do not find out at all.
How This Happens in Practice
Model registries like Ollama, Hugging Face, and cloud provider endpoints use mutable tags. When you pull `nomic-embed-text:latest`, you get whatever version is current today. Pull it again next month and the bytes might be different. The tag is the same. The model is not.
This is the same class of problem that container registries solved years ago. Production teams stopped deploying `python:latest` once the community learned that mutable tags cause silent environment drift. The same lesson applies to model tags, but most teams haven't internalized it yet for ML artifacts.
Incremental embedding is where this becomes dangerous. If you embed your entire document collection once and do not update the model, you are fine because the vectors live in the same space. Most production systems do not work that way. They embed new documents as they arrive and refresh ones that have changed. The moment the underlying model changes, new documents end up in a different space than the old ones, and neither the database nor the retrieval layer knows. The degradation is gradual and cumulative.
What Pinning Looks Like
The fix is version pinning. Use explicit tags, never `:latest`. Record the exact model version with each stored embedding so you can audit which vectors came from which release. Validate at application startup that the configured model matches what the system expects.
For local inference (Ollama, llama.cpp), this means extracting the model files and storing them under your own control. The Modelfile that ships with a model contains the weights, the chat template, the runtime parameters, and the stop tokens. Grabbing only the weights and losing the rest means losing the behavioral recipe the publisher intended. Pin the whole package.
A Pydantic validator that rejects any model reference without an explicit version tag, or any reference ending in `:latest`, catches this at config load. The application refuses to start with an unpinned model. That's a few lines of code doing the same job as the policy engines (OPA, Kyverno) that enterprise ML platforms use to gate deployments. The discipline scales down.
When to Re-embed
If you do need to upgrade the model (better quality, smaller size, new capabilities), re-embed the entire document collection with the new version. This is a migration, not an update. Treat it like a database schema change. Run the old and new versions in parallel against known queries, and cut over when the new one holds up.
The cost of re-embedding is real but bounded. The cost of silent retrieval degradation is unbounded because you don't know it's happening.
By the Numbers
Embedding model updates can shift vector positions by 5-15% in cosine distance, enough to reorder top-k retrieval results without triggering any application error.
Observed in production RAG systems, 2025
Container image pinning adoption exceeded 90% in production Kubernetes clusters after years of silent drift incidents from mutable tags.
CNCF Survey, 2023
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.