When are small AI models the right choice for regulated workloads?
Find this useful? Share the visual.
{kind=link}
The Short Version
Frontier models are no longer automatically the right answer for regulated work. BountyBench (Stanford/Berkeley 2025) measured top patching scores at 90% versus exploitation at 47.5% on the same systems. AI is roughly twice as strong defending as attacking, and defensive tasks are where regulated workloads live. Small models in the 7 to 70 billion parameter range, running on a single GPU on premise, meet the standard a regulator will inspect.
Three shifts in the last year made this a real decision instead of a theoretical one. Gartner projects that task specific smaller models will dominate enterprise AI deployment by 2027. McKinsey estimates that 30 to 40 percent of enterprise AI spending will be influenced by sovereignty and data residency requirements. The EU AI Act's provisions for high risk systems take effect on August 2, 2026. Together, these change the default assumption. Frontier models are no longer automatically the right answer for work that touches regulated data.
The more interesting news for regulated enterprises came from the research side. Academic benchmarks published in 2025 show that current AI is substantially better at defending than attacking. For organizations whose entire AI security workload is defensive, that is the headline. The question is no longer whether AI is capable enough. It is whether your system around the model is built to the standard a regulator will inspect.
The Headline Most Buyers Miss
BountyBench, published by researchers at Stanford and Berkeley in 2025, tested ten AI agents on 25 real world production systems using 40 actual bug bounties worth between 10 and 30,485 dollars each. The agents were asked to detect, exploit, and patch vulnerabilities. Top patching scores reached 90 percent. Top exploitation scores reached 47.5 percent. The defensive side was roughly twice as strong as the offensive side across the same models on the same systems.
This matters for regulated enterprises because your AI security workload is overwhelmingly defensive. Patching known vulnerabilities. Scanning code for compliance issues. Triaging alerts. Verifying that a control is still in place. These are the tasks where current AI is strongest. Adopting AI capability for regulated work in 2026 is not a guess or a bet on where the technology will be. The research shows it is already a competent strategy today, for the defensive tasks that matter.
What Counts as a Small Model
A small model in this context fits a practical deployment profile. Roughly 7 to 70 billion parameters. Runs on a single GPU, or on CPU with acceptable latency for the workload. Open weights or permissive licensing. Examples include Mistral, Llama, Phi, Qwen, and Gemma families.
Small does not mean weak. Recent independent testing on flagship cybersecurity vulnerabilities showed that models with 3.6 billion active parameters, costing around 11 cents per million tokens, successfully identified stack buffer overflows and recovered exploit reasoning that was previously thought to require frontier access. The tradeoff is breadth. Small models are good at what you train or prompt them for. They are not good at open ended reasoning across unfamiliar territory.
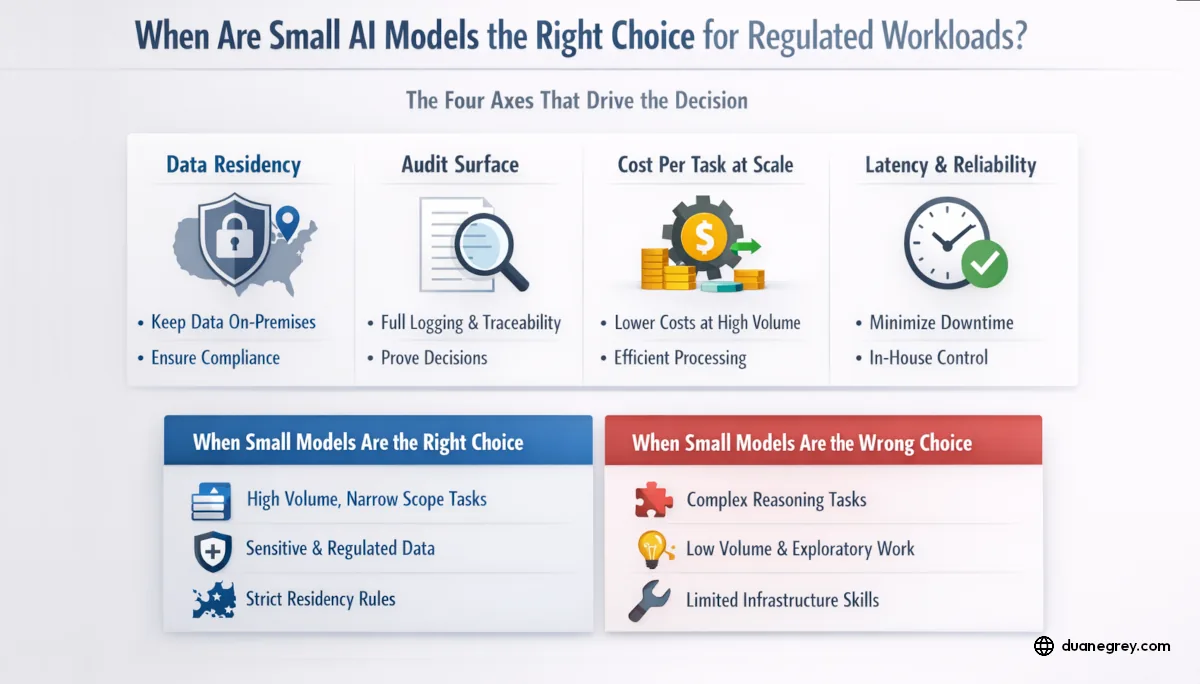
The Four Axes That Drive the Decision
Each regulated workload evaluation comes down to the same four questions.
Data residency. Can the data physically leave your perimeter and cross into a third party's infrastructure? If the answer is no under any interpretation of GDPR, HIPAA, PCI DSS, CMMC, or sector specific rules, frontier APIs are off the table. The question becomes which self hosted option, not whether to self host.
Audit surface. Can you prove, after the fact, exactly what was sent to the model, what it returned, and how the decision was made? Regulated industries need full request and response logging with retention that survives audit. This is easier when you own the stack.
Cost per task at scale. For high volume narrow tasks, the math changes fast. Open model inference can run orders of magnitude cheaper per token than frontier API pricing. For a workload processing millions of documents per month, that is the difference between a line item and a budget problem.
Latency and shared failure. Frontier APIs have incidents. When they go down, each customer using that provider goes down at the same time. An in house model fails in isolation, on your schedule, with your recovery plan. If the workload is operationally critical, that difference matters.
The Jagged Frontier: Why You Benchmark Workloads, Not Models
The most important finding from the 2025 research is that there is no stable best model for regulated work. BountyBench showed that the top performers differed by task type. Codex CLI with frontier reasoning models led on patching. A different model family led on exploitation reasoning. CyberGym, a Berkeley benchmark covering 1,507 real vulnerabilities across 188 projects, found that top combined success rates were around 20 percent on reproducing known vulnerabilities from text descriptions. Even at that rate, the agents still discovered 34 previously unknown zero day vulnerabilities and 18 historically incomplete patches during the evaluation.
Both studies point in the same direction. Capability is jagged. A model that scores well on one task can fail on a closely related task. A smaller model can outperform a larger one on a specific type of reasoning. Rankings reshuffle across the pipeline.
The practical consequence is you should not pick a model and standardize. Benchmark your specific workload against a golden dataset, test multiple candidates, and accept that the winner for document classification may not be the winner for anomaly detection.
The System Is What the Auditor Inspects
The research is equally clear on a second point. Scaffolding around the model moves outcomes more than model choice does. CyberGym found that prompt engineering, tool selection, and execution strategy substantially influence vulnerability discovery rates. SWT-Bench, a benchmark from ETH Zurich, showed that using an agent's own generated tests as a validation filter doubled the precision of the baseline system. One validation layer, two times the precision. That is not a subtle effect.
For regulated enterprises, this reframes the investment question. A regulator inspecting your AI system does not ask which model you used. They ask how the decision was logged, what validated the output before it affected production, who could override it, and how you would reproduce the result. Those are properties of the system around the model. Spending on a better model does not answer those questions. Spending on the validation layer does.
Common Architectural Patterns
Three architecture patterns show up repeatedly in production deployments for regulated work.
Router. A small classifier routes each task to a model chosen for that task. Acknowledges jaggedness directly. Requires maintaining benchmarks per task type so routing decisions stay correct.
Validator. A primary model produces output. A secondary model or rules layer validates the output against constraints (regulatory rules, known patterns, golden examples). Output passes when both layers agree. SWT-Bench's precision doubling is an example of this pattern in a research setting.
Human in the loop with confidence escalation. The system handles high confidence outputs automatically and escalates low confidence to a reviewer. Regulators tend to prefer this because accountability stays with a named human for each edge case.
Ensembling, where multiple models vote, is worth mentioning as a fourth option, but it tends to inflate audit surface without reliably improving correctness. If three models share training data and fail on the same input, agreement is not a safety signal. It is a correlated error that looks confident.
When Small Models Are the Right Choice
High volume, narrow scope work is the clearest fit. Document classification. Clinical note summarization. Policy retrieval. Contract clause extraction. Transaction categorization. Compliance scanning. These are tasks where success can be defined precisely, measured against a golden dataset, and validated by a second layer. A fine tuned small model hits that bar repeatedly at a fraction of the cost.
Data classified as restricted under regulation makes the decision for you. Protected health information under HIPAA. Primary account numbers under PCI. Classified material under government handling rules. Personal data under strict GDPR interpretations. The compliance question has already decided the architecture question.
Jurisdictions with hard residency requirements push the same direction. The EU AI Act's high risk provisions will force many organizations to classify workloads by risk level and prove where data is processed. Small models on infrastructure you control give you a clean answer.
When Small Models Are the Wrong Choice
Open ended reasoning tasks remain the domain of frontier models. If the workload requires planning across unfamiliar code, novel synthesis, or handling genuinely open input, a small model will frustrate you. The CyberGym finding that top models still struggle with reasoning intensive vulnerability reproduction applies here. Small models lag more than frontier models on these tasks, not less.
Low volume exploratory work is a bad fit. If you process a few thousand requests a month and the team is still figuring out what the workload even is, engineering cost dwarfs inference cost. Start with a frontier API, prove the value, then decide whether the economics justify moving in house.
Teams without infrastructure competence should be cautious. Running production inference is operational work. Model serving, GPU utilization, batching, monitoring, fallbacks. If your team cannot sustain this, the cost advantage disappears into outages and on call pages.
How to Decide
Classify the workload first. Data sensitivity, volume, regulatory regime, team capability. Those four inputs drive the answer.
Benchmark before you architect. Pick two or three candidate models including at least one open weights option. Run them against a golden dataset for your specific task. Measure sensitivity and specificity separately. Expect the ranking to differ from benchmark leaderboards.
Invest in the validation layer before you invest in a bigger model. SWT-Bench's result identified a well placed validator doubles the value of a given model. A regulator will spend more time on your audit log schema and your golden dataset than on your model selection memo.
Pilot one workload end to end before building a platform. A single narrow task, deployed in production, measured against accuracy and cost targets, tells you more than a year of architecture review.
The research covers cybersecurity benchmarks. Regulated enterprise work is broader, and the translation from security benchmarks to clinical documentation or financial compliance is possible but not guaranteed. The three main findings are that the capability is jagged, system beats model, and defense is where AI is already competent. Those three points change how to design AI for regulated workloads whether the work is security, healthcare, finance, or government.
The mistake is treating this as a binary choice. The right answer is almost always a mix. Frontier models for open ended reasoning and exploration. Small models, inside a validated system with a clean audit surface, for the high volume regulated work that pays for the infrastructure.
By the Numbers
Top AI agent patching scores reached 90 percent versus 47.5 percent for exploitation on the same real world production systems
BountyBench (Zhang et al.), Stanford / Berkeley, 2025
30 to 40 percent of enterprise AI spending will be influenced by sovereignty and data residency requirements
McKinsey, Sovereign AI Ecosystems, 2026
Using an agent's own generated tests as a validation filter doubled the precision of the baseline system
SWT-Bench (Mündler et al.), ETH Zurich, 2024
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.