Find this useful? Share the visual.
{kind=link}
The Short Version
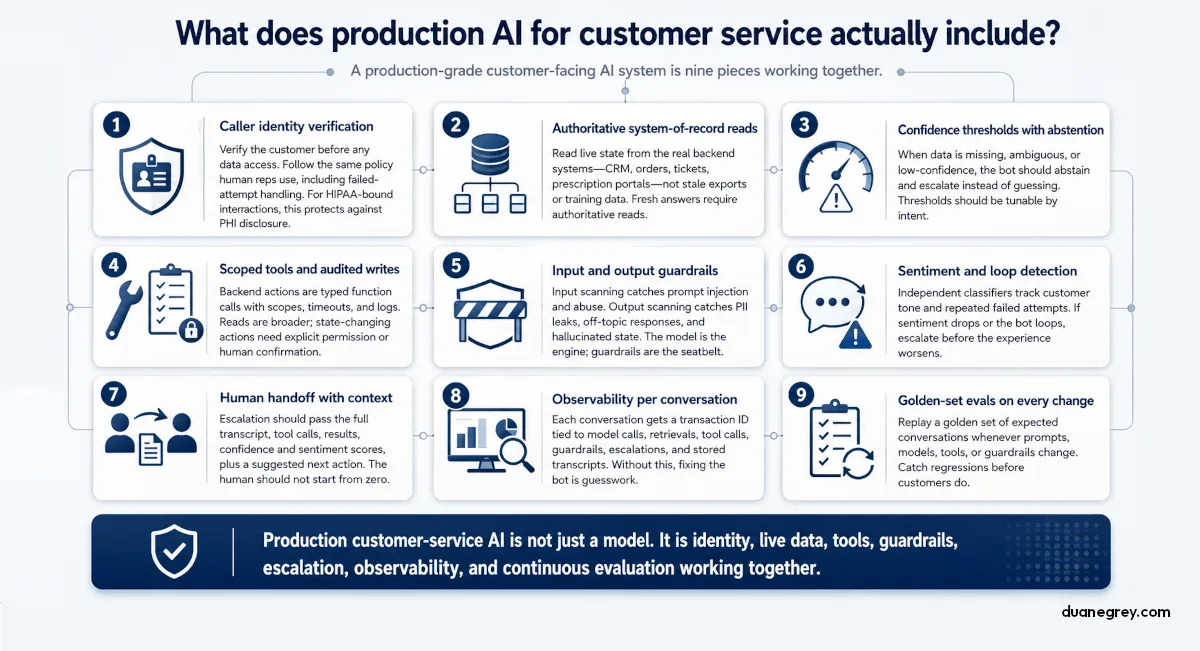
Production customer facing AI is nine pieces working together, not just a model behind a chat widget. The pieces are caller identity verification, authoritative reads against the system of record, confidence thresholds with abstention, scoped tools, input and output guardrails, sentiment and loop detection driving escalation, full context handoff to humans, per conversation observability, and replayable evals on a golden set. Each one earns its place before launch, and the architecture is what separates a system you can stand behind from a chatbot you have to apologize for.
In the companion piece on this site, Is general mistrust of AI a hindrance to businesses adopting AI for client-facing tasks?, the pharmacy story is the anchor. A bot that confidently said the wrong thing, took days to escalate, and started the human at zero when the call finally got transferred. The diagnosis was that the bot was given the model but not the tools and judgment the human rep relies on. This piece is the architecture answer. It describes what a production customer facing AI system contains and why each piece is in it, plus what to ask a vendor if you are not the one building it.
The Layers Worth Naming
A production grade customer facing AI system is nine pieces working together. None of them are unusual on their own. The work is making sure all of them are in place before launch, and that each one talks cleanly to the next.
Caller identity verification before any data access. The bot has to confirm who it is talking to before answering anything about their account. For voice and chat, the verification flow asks for name, date of birth, and at least one additional factor. Common factors include the last four digits of an account number, an address on file, or a recent transaction. The verification flow should follow the same policy your human reps already use, including which questions to ask and what happens after a failed attempt. For HIPAA bound interactions, this step has the same weight as it does for human reps. Releasing PHI to an unverified caller is the kind of disclosure that triggers fines and breach notification.
Authoritative reads against the system of record. The bot reads live state from the same backend systems your human rep checks. These can be order management, CRM, the ticketing system, or a prescription portal. The data should not be a cached copy, a periodic export, or a fine tune of training data that happened to mention some of your customers. The freshness of the answer depends on the bot having access to recent data. The pharmacy bot's failure was an authoritative read it should have had access to and didn't.
Confidence thresholds with abstention. The bot needs to know when it does not know. When retrieval returns nothing, returns ambiguous matches, or returns data the model isn't confident about, the right behavior is to abstain. Saying "I don't see a clean status here" and escalating is the correct answer. Abstention requires the bot to score its own confidence on the data it is grounding in, and the threshold for "answer vs. abstain" needs to be tunable per intent.
Scoped tools with read first and audited writes. The bot's actions on the backend are typed function calls, each with a permission scope, a timeout, and a log entry. Reads are wide open within the customer's own data. Anything that changes state, like refunds, cancellations, or address changes, requires either a human confirmation step or a narrowly scoped permission that the engineering team has explicitly granted to the bot. Each tool call is logged with inputs, outputs, and the conversation id that triggered it.
Guardrails on input and output. Input scanning catches prompt injection (when an attacker hides instructions in a piece of content the bot reads) and abusive language. Output scanning catches PII leaks (the bot returning data from another customer's record), off topic responses, and hallucinated state. Both layers exist regardless of how good the model is. The model is the engine. Guardrails are the seatbelt.
Sentiment and loop detection driving escalation. A small classifier scores each customer turn for tone and intent. A separate counter tracks how many times the bot has tried the same thing without progress. When sentiment trends negative, or when the loop counter passes a threshold, the orchestrator routes to escalation before the customer demands it. This is the piece that decides whether the bot is helping or making things worse, and it has to be a separate indicator from the bot's own self assessment. A confidently wrong bot will not flag itself.
Human handoff with full context attached. When escalation fires, the human receives the full transcript, each tool call the bot made along with results, the confidence and sentiment scores, and a one line suggested next action. The human starts from where the bot left off, not from zero. The handoff payload format is part of the system architecture, not an afterthought.
Observability per conversation. Each conversation gets a transaction id at the channel adapter. That id is bound to the log lines the system emits during the call, covering the model request, tool calls, retrievals, guardrail decisions, and escalations alike. The transcripts are stored, the metadata is queryable, and the daily review process has a place to start. Without this, the work of fixing the bot is guesswork.
Evals on a golden set, replayed on each change. A golden set is a collection of conversations covering the happy paths and the unhappy paths, each one paired with the response the system is expected to produce. Each time a prompt, a model, a tool definition, or a guardrail rule changes, the golden set replays automatically and the diffs surface before the change goes live. This is how regressions get caught before customers do.
When the Bot Should Escalate Itself
Most production systems wait for the customer to ask for a human. A working system has its own trigger list. Six conditions worth wiring up:
- Customer explicitly asks for a human.
- The same intent has been attempted twice without resolution (loop detection).
- Confidence on the data the bot is grounding in falls below the threshold for that intent.
- Sentiment trends negative across the last two or three customer turns.
- The conversation contains content that flags a regulated topic the bot is not authorized to handle, such as legal advice, medical advice, or account closures above a threshold.
- Tool calls have returned errors the bot does not have a remediation for.
When any trigger fires, the handoff payload includes the transcript, the full sequence of tool calls and their results, the confidence and sentiment scores at the point of escalation, the trigger that fired, and a recommended next action drawn from a small library of patterns the engineering team has reviewed. The human has the call assembled in front of them by the time they pick up.
Regulated Industries Need More
Healthcare, finance, legal, and insurance carry rules that change the architecture. The model provider needs to be under an agreement that covers the regulated data, such as a BAA for HIPAA or the equivalent in other regimes. Personal information should be redacted before the model call, not after. Transcripts have to be retained and audited the same way other customer interactions are. The audit log itself needs integrity protection so it cannot be quietly altered. For some contracts and some jurisdictions, the inference has to run on dedicated infrastructure, on premises or in a virtual private cloud, rather than a shared API endpoint. None of these add functional capability. They add operational rigor that you cannot bolt on after launch.
A Reference Architecture
A working stack, outermost on inbound to innermost.
Channel adapter. Voice via Twilio or equivalent with a speech to text layer like Whisper. Chat via a widget on your site or an embedded SDK. The adapter normalizes turn input, assigns the conversation id, and hands off to the orchestrator.
Conversation orchestrator. Python service built on FastAPI. Owns the state machine for the call, manages turn taking, dispatches tool calls, runs the escalation router, and decides when to call the model. Stateless per request but reads conversation state from the database on each turn.
Guardrail middleware. Input scanning runs before the model sees the turn. Output scanning runs after the model produces a response and before the response reaches the customer. Both layers log each decision they make.
Identity verification gate. Sits between the guardrail middleware and the data layers. The orchestrator routes the first turn through a defined verification flow and gates each subsequent tool call against the verified state. Unverified callers can still ask general questions that the knowledge layer can answer, but they cannot reach any tool that touches their account.
Knowledge layer. PostgreSQL with pgvector for retrieval against policies, FAQs, and procedures. Embeddings on a small local model. This layer answers "how does this work" questions. It does not answer "what is the status of my order" questions, because those are tool calls against the system of record.
Tool layer. Typed function registry. Each tool has a Pydantic input schema with strict validation, a timeout, a permission scope, an idempotency key on writes, and a structured result the model is forced to parse. The model can only call tools the registry exposes for the current intent.
Sentiment and intent monitor. Small classifier running on a local model. Cheap, low latency, runs on each customer turn. Outputs a sentiment score and an intent label that the orchestrator uses for escalation decisions and for analytics.
Escalation router. A configuration driven module that reads the trigger list, packages the handoff payload, and pushes to the human queue, whether that is Salesforce Service Cloud, Zendesk, or an internal app your reps use.
Observability sink. Structured logs keyed by conversation id and a per turn transaction id. Stored in a queryable backend, Postgres for low volume or ClickHouse or BigQuery at higher volume. Analytics dashboards read from this sink, not from the live system.
Engineering Choices Worth Making
Python and FastAPI for the orchestrator. The system is I/O bound. Voice and chat are network conversations, and async Python handles concurrency cleanly without a thread per call.
PostgreSQL with pgvector for both conversation state and knowledge retrieval. One database, one operational profile, one backup strategy. Schema version checked at startup, and the service refuses to boot on a mismatch.
Pydantic models with `extra="forbid"` on API requests, tool inputs, and database row shapes. Unknown fields raise on construction. This catches typos in client payloads, prevents mass assignment, and gives each boundary a typed contract.
Structlog with a transaction id bound at the channel adapter. Each log line in the conversation carries the id. When something breaks, the support engineer can grep one id across the orchestrator, the tool calls, the model requests, and the audit log without piecing logs together by timestamp.
Typed tool registry with permission scopes. Tools are not dispatched by string name or by evaluating a model's free text response. The model picks a tool from a registered set, the orchestrator validates the inputs, checks the scope, and calls the function. No `eval`, no shell out, no dynamic dispatch from untrusted strings.
Split LLM stack. The generation model, the one producing customer facing responses, lives behind an enterprise contract with data handling terms that match your industry. The sentiment and intent classifier is small enough to run locally on a few hundred million parameters, which gives you low latency and zero per call cost on a turn that fires on each customer message.
Audit logging at two tiers. Anything that moves money, changes PHI, or changes state on the customer's account goes to a Tier 1 audit table in the same transaction as the action. Anything that decides who can do what, like escalation decisions, guardrail triggers, and permission checks, goes to a Tier 2 async log. The two tiers have different retention and different failure semantics.
What Buying This Looks Like
Most companies are not going to build this from scratch. The point of naming the architecture is so you know what questions to ask the vendor.
Ask how the bot verifies caller identity and what data access is gated on that verification. Ask whether the bot reads from your system of record live or from a cached export. Ask how the bot escalates on its own, what triggers it, and what the human receives at handoff. Ask what input and output guardrails are in place and how they are tuned. Ask for the eval methodology and a sample of a recent golden set replay. Ask what the audit trail looks like for a single conversation. Ask what the contract terms are for the model provider and whether they match your industry's compliance requirements.
If the vendor cannot answer those questions in plain language, you are buying a chat widget with a model behind it. The architecture is what separates that from a system you can stand behind when a regulator, a customer, or your own engineering team asks how it works.
By the Numbers
81% of consumers expect chatbots to escalate to a human when needed, but only 38% report that this happens always or often.
Zoom + Morning Consult, 'AI alone won't save CX. Resolution will' report, 2025
Salesforce projects that AI will resolve 50% of service cases by 2027, up from 30% in 2025, which makes the architecture around escalation and oversight matter for most consumer brands.
Salesforce State of Service Report, 7th Edition, 2025
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.