What is the right architecture when the AI brain itself cannot be trusted?
Find this useful? Share the visual.
{kind=link}
The Short Version
If the model itself cannot enforce a security boundary, the boundary has to live somewhere else. Six layers carry the architecture instead, each outside the model. Even the most architecturally serious permission gate shipped in production today is measurably leaky under adversarial workload.
In June 2025, security researchers at Aim Labs disclosed a vulnerability in Microsoft 365 Copilot that let an attacker exfiltrate user data through the assistant itself. The attack required no user interaction. An email landed in the inbox with a hidden instruction in the body, and the next time the user asked Copilot for help with something routine, the instruction took over. The vulnerability has a CVSS score of 9.3. Microsoft patched it on the server side. No client patch was issued because that class of problem cannot be fixed there.
The problem is not Copilot. The problem is what happens when any AI agent reads content the user did not write. An email body, a web page returned by a search tool, a README file in a repository the agent has been asked to review. The model cannot tell the difference between instructions from the user and instructions hidden in the content being processed. This is prompt injection. Better prompting does not reliably solve it. Neither does fine tuning. Anthropic's own engineering team published a design document explicitly assuming Claude can be tricked into following injected content, and they put the security boundary somewhere else.
What the research is saying
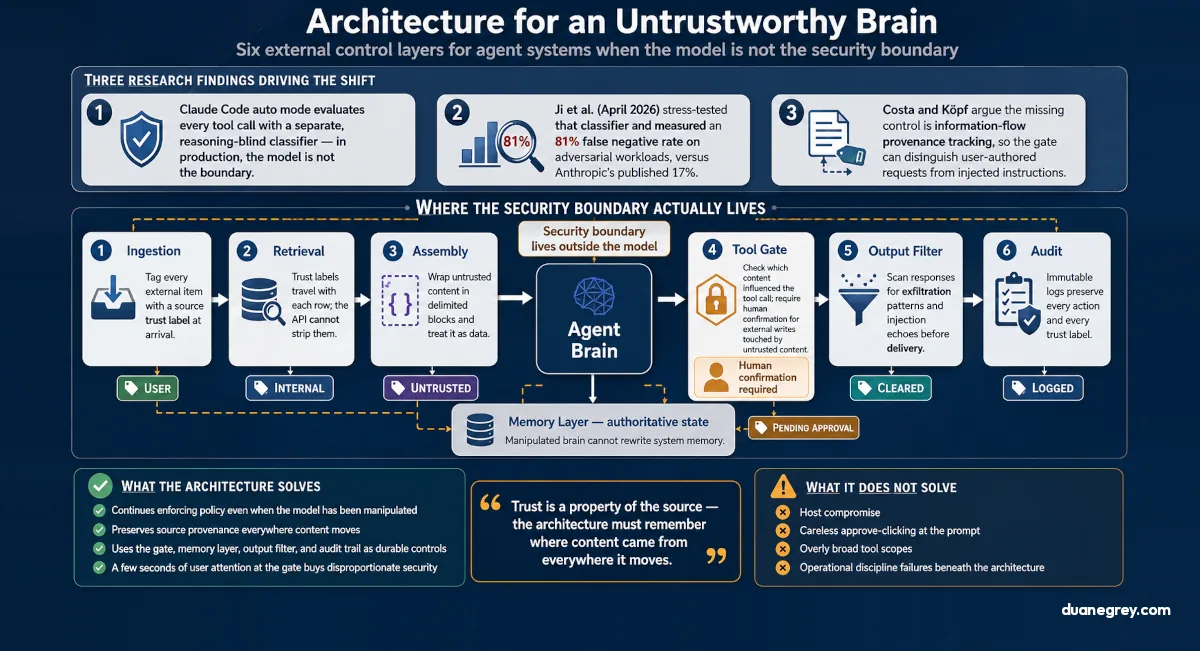
Three findings, taken together, suggest the conversation about AI agent security has already shifted from a model problem to an architecture problem.
The first is Anthropic's auto mode, the safer permission feature in Claude Code. The published design uses a separate classifier to evaluate every proposed tool call before execution. The classifier is blind to reasoning by design. It looks at the raw user prompt and the proposed tool action. It does not look at Claude's own generated reasoning about what it is doing. The logic is straightforward. If Claude has been manipulated by injected content, Claude's reasoning about its own behavior cannot be trusted, so the safety check ignores it entirely. This is Anthropic saying, in production, the model is not the boundary.
The second is an independent stress test of that same auto mode. Ji et al. published Measuring the Permission Gate in April 2026, an evaluation of Claude Code's classifier against a benchmark of 128 prompts and 253 actions designed to slip past it. The reported overall false negative rate is 81%. Anthropic's own published figure is 17%. False negative rate measures how often the classifier missed an action it should have caught, and the gap between the two numbers is the gap between a controlled lab evaluation and an adversarial workload. Even the most architecturally serious permission gate shipped in production today is, by independent measurement, leaky.
The third is the academic work pointing at what the missing piece is. Costa and Köpf's recent paper on securing AI agents with information flow control argues that the defense agents need is not better permission gating on tool calls alone. It is provenance tracking on the data the agent reads, so that the framework knows when a tool call has been influenced by external content. Without that tracking, the gate cannot reliably distinguish a real user request from an injected instruction.
Put these three findings together and the problem statement becomes clear. The model is known by its own makers to be manipulable. The classifier built to compensate is leaky under adversarial workload. The provenance layer the academic work names as missing has not yet shipped as a default in the agent platforms I have read about.
Where the security boundary lives
If the model itself cannot be trusted to enforce a security boundary, the boundary has to live somewhere else. The diagram below shows where. User prompts and external content enter as two separate streams with different trust labels. The labels travel with the content through retrieval, prompt assembly, and into the model. When the model proposes a tool call, a gate outside it checks which sources influenced the decision and asks for human confirmation when external content is in the mix. Authoritative state lives in the memory layer, not in the model, so a manipulated reasoning step cannot rewrite what the system remembers.
Six layers that are not the model
The architecture I keep coming back to has six layers. None of them are the model.
1. Ingestion. When external content arrives, the system tags it with its source trust label the moment it enters storage. An email body coming in from the user's inbox is labeled untrusted external. A direct prompt the user typed is labeled trusted user. The agent itself, generating a summary or a decision log, is labeled trusted system. The label is mandatory, not optional. It is part of the schema, not metadata the framework can decide to drop later.
2. Retrieval. When the agent fetches that content from storage, the label travels with the row. The retrieval API does not have a simplified return shape that strips the label off. Code that wants to ignore the label is the bug, not the rule.
3. Assembly. When the agent builds a prompt, untrusted external content is wrapped in delimited blocks, and the system prompt tells the model to treat the contents of those blocks as data, not as instructions to follow. This does not solve prompt injection. Current models still occasionally follow carefully crafted injections even inside delimited blocks. It raises the difficulty meaningfully, and it gives the rest of the architecture a clean handle to grab onto.
4. Tool gate. Before any tool call runs, the gate inspects what content influenced the decision. If the influencing set contains untrusted external content and the tool's permission scope includes external writes, sending email, posting to a webhook, transferring funds, the call is either denied automatically or escalated to the user for confirmation. This is the layer that does the actual security work. The rest of the architecture exists to make this gate trustworthy enough to enforce.
5. Output filter. Before any response reaches the user, it is scanned for compromise indicators. Data exfiltration patterns, text shaped like instructions the model may have absorbed and repeated, suspicious link constructions. This catches the case where the model encoded an injection into its own output, asking the user to click something or paste something elsewhere.
6. Audit. Every step is logged with the trust labels preserved. The decision log records which content was retrieved, which content influenced which tool call, what the gate decided, and whether the user confirmed or denied. Records are immutable. Trust labels can degrade after the fact, an item flagged "treat as data" lowers the effective trust of any decision it influenced, but the original label is never overwritten.
The first two layers and the last one are about provenance. They are about knowing where data came from, and keeping that knowledge alive through retrieval and audit. From what I have read of open source agent platform documentation, those three layers do not show up as default behavior. The middle three layers are usually configurable, but the framework does not enforce them. The defense is left for the developer to wire up correctly.
What this looks like in practice
The architecture above is the target state. The next diagram zooms in on a single attack and traces a hostile email through every guardrail in sequence. The brain in step six may or may not follow the injection. The point of steps seven through eleven is that the architecture has to hold even when the model fails.
What I am building today is narrower than this. The current state is a planner that produces structured plans for inspection by hand, not for execution. The reason this cannot do damage today is that nothing is wired up. The architecture itself does not prevent anything yet. That is the honest part. The target state has the executor wired, the memory layer writing trust labels at ingestion, the tool gate intercepting calls influenced by external content, and the user in the loop for any external write the gate flags.
My Observations
A few things I keep coming back to as I build this.
The model cannot enforce its own security boundary. Treating it like it can is the underlying mistake. The frameworks I have evaluated ship defaults that have the model decide whether a request is safe. The researchers I have read on the topic in the last year argue this is exactly what cannot work. Anthropic's auto mode is the closest production attempt at moving the boundary off the model, and the stress test paper still measures it at 81% leaky.
Trust is a property of the source, not of the content. The architecture has to remember where every piece of content came from, everywhere that content moves. A summary of an untrusted email is still untrusted. An embedding of an untrusted document is still untrusted. The label does not get laundered by paraphrasing or vectorizing.
A few seconds of user attention buys more security than most things in the stack. The cost of pausing to confirm is low, the cost of a wrong action is sometimes catastrophic, and the gap between the two is what makes a confirmation prompt one of the cheapest security controls available. The rest of the architecture exists to make the confirmation prompt smart enough that the user only sees it when they need to think.
What this architecture does not solve
A determined attacker with code execution on the agent host bypasses every layer. A user who clicks approve on the confirmation prompt without reading defeats the gate. A tool registry with overly broad scopes undermines the chain regardless of trust labels. The architecture relies on the operational discipline of whoever sets up the system, classifying data trust correctly at ingestion, designing scheduled jobs with awareness of what data they pull in, scoping tool permissions tightly. Those are not architectural problems. They are security process problems that sit underneath the architecture, and the architecture cannot rescue you from getting them wrong.
Six questions for the agent you use
The six questions are not a critique of any specific platform. I have not audited them all, and the space moves too fast for me to credibly call out specific products. What the questions are good for is opening the documentation of whatever agent you use, and looking for the layers.
- When external content is saved in your agent's storage, does the system know it is external the moment it arrives?
- When the agent retrieves that content later, does the data label survive every fetch?
- When that content goes into a prompt, is it visually separated from your instructions?
- When the agent proposes an action influenced by external content, does anything check before execution?
- Does anything scan the agent's response before it reaches you?
- If something breaks tomorrow, can you trace which content drove the action?
The questions are layered. Any one of them could be answered yes while others are no. The three that are most often missing are the provenance questions, the first, the second, and the last. Those are the ones that let the rest of the architecture work.
Read the documentation of the agent you use daily. Find the layers. Where they are not addressed, that is an honest place to ask the vendor or maintainer harder questions, before a mistake occurs.
By the Numbers
Aim Labs disclosed a prompt injection vulnerability in Microsoft 365 Copilot, tracked as CVE-2025-32711 with a CVSS score of 9.3, requiring no user interaction and allowing an attacker to exfiltrate data through a hidden instruction embedded in an inbound email.
NVD entry, CVE-2025-32711 (EchoLeak), disclosed by Aim Labs, June 2025
An independent stress test of Claude Code's auto-mode permission classifier reported an overall false negative rate of 81% across 128 prompts and 253 adversarial actions, against Anthropic's own published figure of 17%.
Ji et al., 'Measuring the Permission Gate: A Stress-Test Evaluation of Claude Code's Auto Mode,' arXiv:2604.04978, April 2026
Securing AI agents against prompt injection requires information flow control on the data the agent reads, so the framework knows when a tool call has been influenced by external content. Permission gating on tool calls alone is insufficient without that provenance tracking.
Costa and Köpf, 'Securing AI Agents with Information-Flow Control,' arXiv:2505.23643
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.