Find this useful? Share the visual.
{kind=link}
The Short Version
Enterprise AI conversations are shifting from adoption to right sizing as finance starts asking why the bill is so high. The cost question has an architecture answer underneath it, not a vendor answer, and the work companies are doing with AI does not need a frontier model. A tiered architecture with a router and an AI gateway is the shape the conversation is moving toward, and the first practical move is observability on current traffic, not a redesign.
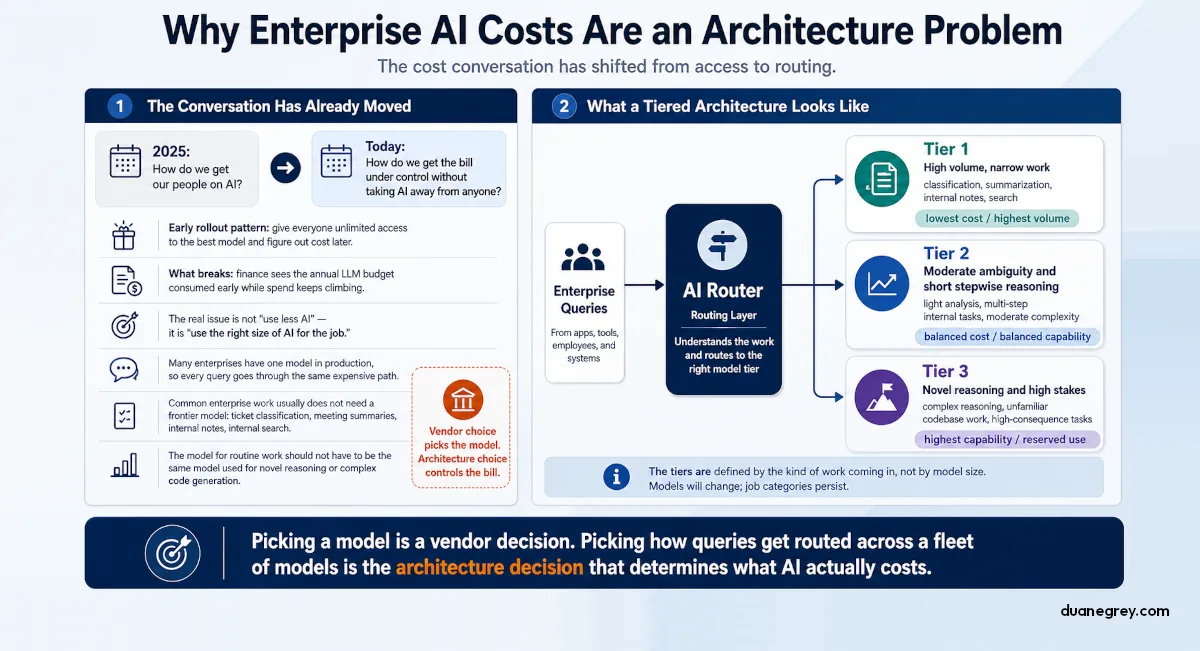
In 2025, the question in enterprise adoption conversations was "how do we get our people on AI." Today, in the same rooms, the question is "how do we get the bill under control without taking AI away from anyone."
The conversation has moved. Early on, the move was to hand employees unlimited access to the best models on the market and figure out the bill later. That worked when budgets were exploratory and AI was a strategic bet. It stops working when finance announces that the LLM budget for the year has been used within the first quarter and the rate of spending is an upward trajectory.
What replaces it is not "use less AI." It is "use the right size of AI for the job." Enterprise teams are arriving at this question without having built the architecture that lets them answer it. They have one model in production. Every query goes through it. The bill reflects that.
The work companies are doing with AI is not work that needs a frontier model. Classifying tickets, summarizing meetings, drafting internal notes, searching internal knowledge. The model that handles these jobs well does not have to be the same model that handles novel reasoning or code generation against an unfamiliar codebase. Treating them as if they do is the line item on the invoice nobody talks about.
The architecture decision is the conversation enterprise teams are about to have. Picking a model is a vendor decision. Picking how queries get routed across a fleet of models is the architecture decision that determines what AI costs.
What a Tiered Architecture Looks Like
A tiered architecture is three model classes sitting behind a router. The tiers are defined by the kind of work coming in, not by the size of the model. That definition is the part that gives the architecture shelf life. The model market churns; the tiers describe jobs, and jobs do not churn the same way.
Before naming the tiers, three questions define what complexity means for routing.
How predictable is the input shape? A support ticket has a known format; an open ended research question does not. How deep is the reasoning? Pulling a date out of a contract is shallow work, while comparing the obligations of two contracts is deep. What is the cost of a wrong answer? A misclassified help desk ticket is cheap to fix. A wrong summary of a legal document can cost much more.
A query that scores low on all three belongs at the cheapest tier. A query that scores high on any of them needs to escalate.
Tier 1 is high volume, narrow work. Classification, extraction, knowledge base lookups, templated responses. The model has to recognize the shape of the input and return a structured answer. The work looks like routing a support ticket to the right queue or pulling an invoice number out of an email. Most enterprise traffic lives at this tier.
Tier 2 is moderate ambiguity and short stepwise reasoning. The model has to understand context that is not perfectly structured and respond coherently across more than one turn. Summarizing a meeting transcript and answering a related question about it, or drafting an internal note from a set of bullet points. The work is harder than Tier 1 but does not require a frontier capability.
Tier 3 is novel reasoning and high stakes. Working through a regulatory question that crosses two jurisdictions, or generating a deployment script against an internal platform the model has not seen before. The work that genuinely needs the largest model on the market. Tier 3 volume should be rare in a well routed setup.
Enterprise teams that have measured their AI traffic find that Tier 1 is the majority of volume and Tier 3 is the exception. The single model setup routes all of it through the model built for Tier 3. The cost reflects the choice of architecture, not the complexity of the work being done.
The Router Is the Piece Nobody Talks About
Everyone talks about the models. Few people talk about the thing that decides which model gets the query. The router is the difference between an architecture that saves money and an architecture that adds latency on top of the bill it was supposed to reduce.
The router has four jobs.
First, classify the incoming query. Run each query through the three questions from the previous section and score the result. The classification has to happen fast and cheaply, because every query pays the routing tax before it pays the model tax.
Second, route to the cheapest tier likely to succeed. The router is not picking the smartest model. It is picking the smallest model that can handle this specific query. A request for a meeting summary does not need the same model as a request to compare two sets of regulations.
Third, detect a weak answer and escalate. When the Tier 1 answer looks weak, the router sends the same query to Tier 2. Weak can mean a short response, low confidence, or wandering from the question. Escalation is the difference between an architecture that protects quality and one that hides errors.
Fourth, log each routing decision. The log captures which tier handled the query and what the model returned, plus a hindsight judgment on whether the routing was right. Without that record, there is no way to tune the router or audit cost, and the architecture stops improving the day it ships to production.
The hard part. The router itself is a model. A small model that runs fast and cheap, ideally, but still a model. A bad classifier sends complex queries to Tier 1, where quality collapses. An overly cautious classifier sends every query to Tier 3, where the benefit of tiering disappears. The router has to be tuned like any other model in production, and that tuning is the work that determines whether the architecture pays off.
This is the part of tiered architectures that fails most often in practice. Enterprise teams build the three model tiers, deploy the router, declare the work done, and stop measuring. Six months later the router is silently sending eighty percent of traffic to Tier 3 because no one has audited its decisions. The bill looks like the single model setup it was supposed to replace.
How to Tell If You Would Benefit From Tiering
The architecture has obvious appeal. The question for an enterprise team is whether the work coming through the AI stack today splits the way the tiers describe, or whether the volume is weighted toward Tier 2 and 3 work that would not benefit from a Tier 1 lane.
Two questions answer this.
What share of current queries could a smaller, cheaper model have answered correctly? If a team can answer this with a number from production logs, they are halfway to a tiered architecture already. If the answer is "no idea," that is also an answer. It means the AI stack has no observability on what it is being asked to do, and the conversation needs to start there.
Of the queries that hit the most expensive model in production today, how many genuinely needed that model? A short summary of a meeting transcript reaching the same model used to analyze regulations across two jurisdictions is a sign the routing decision is being made by accident. The bill is the consequence of a routing decision nobody is making.
The honest tradeoff. Both questions assume the team has the observability to answer them. Production AI traffic without logging each query individually cannot be diagnosed. The first move toward a tiered architecture, for a team that has not done this work, is not building the router. It is instrumenting the current setup well enough to know what the router would have to handle.
A common audit looks like this. Pull a week of production traffic and classify each query by hand into the three tier buckets from earlier in this piece. Then count the volume in each tier. If Tier 1 is more than half of volume and Tier 3 is rare, the tiered architecture will pay back. The opposite case is volume concentrated in Tier 2 with little Tier 1 work, which gives smaller savings and may not justify the router engineering effort. A team whose work concentrates in Tier 3 has a different answer entirely. They genuinely need frontier capability, and tiering is not what fixes the bill.
Where This Goes Wrong
A tiered architecture can fail in ways the team did not see coming. Four are common enough to name.
The router has no observability. The architecture is deployed, the tiers are running, and nobody can answer the question "what percentage of queries went to Tier 1 last week, and how many of those got escalated to Tier 2." The router became a black box the day it shipped. Without metrics on tier hit rates and escalation rates, the architecture cannot be tuned. It also cannot be defended when finance asks whether it is saving money.
Tier 1 is tuned too aggressively. Each edge case the team encountered in development became a reason to escalate. The router now sends a third of traffic that should have stayed at Tier 1 up to Tier 2 instead. The benefit of tiering shrinks until the architecture is effectively a two model setup with extra latency. The fix is usually to widen Tier 1's tolerance and accept that a small share of Tier 1 answers will be slightly worse than what Tier 2 would have produced.
The router routes to Tier 3 by default. The classifier is in place. The escalation logic is in place. But the team is nervous about Tier 1 quality on important queries, so the threshold for escalation is set conservatively, and most traffic ends up at Tier 3 anyway. The architecture is decorative. The bill is the same as the single model setup it replaced. This is the most common cause of "we tried tiering and it didn't save us anything."
There is no escalation path when Tier 1 returns a bad answer. Tier 1 returns a response that looks plausible but is wrong. The router has no confidence check on the response, so the answer goes back to the user. The system has worse quality than the single model setup it replaced, because the model handling the query is not the model the original architecture would have used. The fix is a confidence score on Tier 1 outputs and an escalation rule that triggers on low confidence, not on response length alone.
These problems are downstream of the same root issue. A team that cannot see what its router is doing cannot fix what its router is doing.
Where to Start
The first move toward a tiered architecture is not building the tiers. It is building the layer that lets the team see what their AI traffic looks like.
That layer is an AI gateway. A gateway is a proxy that sits between internal applications and the upstream AI providers. Each call from internal code to Anthropic, OpenAI, or any other model vendor is rerouted to flow through the gateway, which forwards the request to the original provider and returns the response. Done right, the gateway is transparent. Existing applications keep working without code changes beyond the base URL.
The gateway is where the work happens. It logs each query that leaves the company. It is also where the router attaches once the tiers are designed, and where finance can enforce budgets by team or by application when they start asking. Without a gateway, there is no place in the stack that sees all AI traffic. With one, downstream architectural decisions become possible.
Three steps, in order.
First, stand up the gateway and route one application's traffic through it. The right first application is the smallest active AI consumer in production, not the largest. Large applications come later, once the gateway has been proven transparent on a low risk workload. The deliverable at the end of this step is a validated migration pattern and observability on one workload, not enterprise wide visibility.
Second, expand coverage. Migrate the remaining applications one at a time, working from smaller to larger AI consumers as confidence in the gateway grows. Each migration should be invisible to the application's users. By the end of this step the gateway sees each AI call leaving the company, and the team has a week or two of production logs to analyze.
Third, do the audit from the previous section. With real logs that capture individual queries, the team can answer the two diagnostic questions and decide whether tiering will pay back. Only at this point is it worth picking a smaller model for Tier 1 and designing the router. The architecture the rest of this piece described becomes implementable from here.
The build or adopt decision. Several commercial gateway implementations exist today, with different stances on what the gateway owns. Examples include LiteLLM, Portkey, Helicone, and the Cloudflare AI Gateway. The decision is a tradeoff between time to value and control over the stack. For a team whose AI spend is climbing fast and whose engineering bandwidth is thin, adopting an existing gateway gets observability in place faster than building one. For a team that has specific compliance, data residency, or integration requirements that the commercial options do not address, building thin makes sense.
Either way, the gateway comes first. The router and the tiers come after.
Teams that get this right treat AI as a fleet decision and instrument it like one.
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.