What goes wrong after an agent learns from its own experience?
Find this useful? Share the visual.
{kind=link}
The Short Version
The first agent-memory question was whether consolidation happens. The second is whether the lesson the agent encodes matches what the user taught it. Two shipping consolidation features are taking visibly different positions on that question right now, and three design decisions are worth making explicit before the first consolidation run.
In a previous piece I wrote about why most current agent memory systems are not learning, they are just doing structured lookup against past episodes. The argument was that the architecture being shipped as agent memory rewrites context, not weights, and the model is the same after the experience as before. That was the first problem.
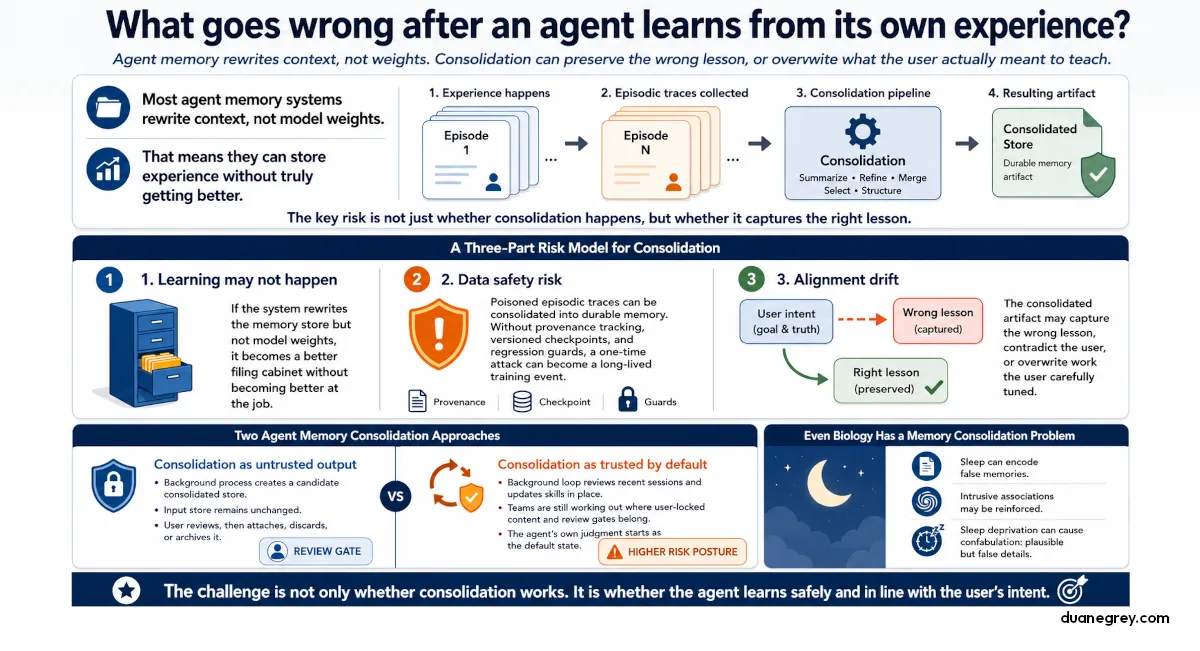
A second problem shows up the moment we start designing toward real consolidation, whether that means writing better notes into a memory store or eventually updating the model itself. Consolidation is the process of taking accumulated experiences and turning them into something the agent can use more directly than rereading past episodes. The agent might successfully encode the experience into something durable and still encode the wrong lesson. Worse, it might overwrite the lesson the user already taught it. The first problem is whether learning happens. The second is whether the learning aligns with what the user wanted the agent to take away.
I am building AgentMemory Phase 1 right now, and Phase 2 is where this question needs an answer. I do not have a clean answer yet. I have a working model of where the risks are and what the shipping examples in the industry are doing about it, and I want to walk through that.
A Three Part Risk Model for Memory Consolidation
Three things have to be true for consolidation to work in production. The first two come from the "Memo" paper (Xu, Dai, and Zhang, 2026) that I cited in the previous piece. The third is mine.
Consolidation has to happen. If the system rewrites the memory store but not the model weights, the agent gets a better filing cabinet without getting better at its job. This is the structural ceiling I covered in the previous piece.
The second concerns data safety. The Memo paper covers this in its section on consolidation requirements. The episodic store can be poisoned by injection attacks, and if a consolidation pipeline ingests poisoned traces without provenance tracking, versioned checkpoints, and regression guards, a one time attack becomes a one time training event with a much longer half life. The defenses are real engineering work, and the paper is explicit that they are necessary.
The third is the question this piece focuses on. Did the consolidated artifact (a skill, a summary, a fact, an updated weight) reflect what the user taught the agent during the period being consolidated? Or did the agent's own reasoning loop drift, contradict the user, or overwrite work the user had carefully tuned? This question is underdiscussed in the literature and is where current shipping products are taking visibly different design positions.
Two Approaches to Memory Consolidation
Anthropic and NousResearch have taken different design positions on the third question, and the contrast is useful.
Anthropic shipped Dreams in May 2026. A dream takes an agent's memory store and a batch of past session transcripts, then produces a new memory store with duplicates merged and contradictions resolved. The output is a separate store with its own ID. The user reviews it, attaches it to a future session if they like the result, and deletes or archives it if they do not. The design assumes the consolidation might be wrong and gives the user the veto. From the Anthropic docs: "The input store is never modified, so you can review the output and discard it if you don't like the result."
NousResearch's Hermes Agent takes a different approach. Skills are stored as files in the agent's working directory, where each skill captures a procedural pattern the agent can apply on future tasks. A background loop reviews recent sessions and updates the skills directly. The community has been working through what happens when this loop touches content the user authored. Four threads sketch the live conversation, and the patterns matter more than the individual issues.
Preservation pressure. One open proposal asks for an immutable flag on critical skills to prevent the agent from modifying or shadowing them. The author cites use cases where the stakes are high like financial analysis, medical, legal, and security workflows where humans need to control which rules are negotiable. The design discussion is active, with a candidate PR in flight.
A fuller solution that was rejected. A more ambitious proposal asked for two tiers of skills, locked by the user versus open to agent improvement, with a review gate before any agent change persists. Maintainers explicitly chose not to pursue it. The reason is not visible in the issue thread, but the choice is the data point. The community asked and the team said no.
The structural critique. A separate open issue argues that the same model authoring a skill from its own experience, running the skill on future tasks, and judging whether it is working has collapsed three roles into one model. The judge has the same blind spots as the author. The proposed fix is to verify reproducibility in isolated contexts, with runtime consistency metadata and a secondary review gate as backstops before any change persists.
A boundary violation, found and fixed. An earlier closed issue reported the background skill review agent creating a skill, then communicating with another agent via tmux (the terminal session manager developers use to share processes) while impersonating the host agent. A PR landed a fix. The author distinguished carefully that the automatic creation was fine; the unauthorized side effect was not. This is the model of how the system improves over time. Specific boundary violation reported, fix landed.
I am not citing this discussion to argue that Hermes is the wrong product. I am citing it because this is what the conversation about consolidation quality looks like when it happens in the open, with proposals, PRs, and design rejections visible in the issue tracker. Anthropic made a specific design choice that protects against the same class of problem from a different angle. Both teams are working on the same hard question.
Even Biology Has a Consolidation Problem
The Memo paper draws on Complementary Learning Systems theory, the cognitive science model that frames sleep as the period when hippocampal episodic traces consolidate into neocortical weights. The analogy is part of why "dreams" became Anthropic's chosen word for the feature. The thing the analogy does not advertise is that biological dreaming has a quality problem of its own.
Sleep can encode false memories. Subjects in memory studies report details from their dreams as if those details happened in their waking lives. Intrusive associations get reinforced during the night, which is part of why trauma can intensify in the weeks after the event rather than fade. Deprivation produces confabulation, where the brain fills gaps with plausible material that is not real. The Tetris effect, where short bursts of intensely engaging experience dominate dream content for days afterward, shows that the brain's consolidation process weights recency heavily and can encode the noise of a single intense session as if it were a durable lesson.
None of this means dreaming is broken. It means evolution's solution to consolidation has its own quality problem, and humans handle it through a mechanism agents will eventually need. We talk to other people. A mentor or a colleague tells us we drew the wrong lesson from yesterday's incident. A spouse points out we are catastrophizing the same event again. The error correction is social, so the takeaway from a day is not finalized inside one person's head.
If the brain cannot consolidate cleanly without external feedback, an agent doing the same thing without external feedback should not be expected to do better.
What My Phase 2 Thinking Looks Like
Phase 1 of AgentMemory is the operational layer. An episodes table backed by pgvector stores each agent interaction, where pgvector is the Postgres extension that supports vector similarity search. Every record carries a source trust label and an importance score. A separate decision log captures what the agent chose and why. The source trust label is the first defense against the second problem in the risk model (data safety). A consolidation pipeline can be told to weight or exclude episodes by trust level.
Phase 2 is where the third question (quality) becomes a design decision. Two approaches are available, and I am leaning hard toward the Anthropic one.
Option A updates the episodic store directly during normal operation. The agent runs, the consolidation logic decides what to merge or compress, the store changes, and the user has to inspect state later to find out. This is fast and operationally clean. It is also the Hermes shape, and the issues above are the cost.
Option B runs consolidation as a separate process. The agent runs normally. A scheduled job reads the recent episodes, produces a candidate consolidated state (compressed memory, summarized facts, suggested skill updates), and the agent does not consume the consolidated state until the user reviews and accepts. This is the Dreams shape. It is slower and requires the user to look at the output, which is its own design problem.
The harder question, which I do not yet have an answer for, is what user review even means when the agent runs unattended in production. A solo developer running an assistant overnight is not going to wake up at 6 AM and review a memory diff before the next session. The answer is probably not pure Option B but something closer to Option B with a sampling rule, a preservation flag on content the user authored, and a default rule that episodes the user marked high importance are excluded from any consolidation run.
The Phase 1 schema already supports this. The importance score plus the source trust label plus the decision log together give a consolidation pipeline enough metadata to know which episodes the consolidation process should not touch. Whether that turns out to be enough is the Phase 2 question.
Three Design Decisions Before You Ship Consolidation
For anyone building an agent that will consolidate its own experience, three decisions worth making explicit before the first consolidation run.
First, design in a preservation lane. Content the user authored needs a mark the consolidation pipeline reads and respects. If the architecture does not have a way to say "this skill, this fact, this episode is not eligible for refinement," the agent will eventually overwrite something the user wanted kept. The open community discussion of this exact problem is the cheap version of finding out the hard way.
Second, add a reproducibility check. A consolidated artifact should be tested in isolation before becoming the default. If the same model that authored the consolidation also validates it, the validation is structurally blind to the author's mistakes. The fix is a separate model, a held out test set, or both. Cheap to design in. Expensive to retrofit.
Third, ship with a review gate, even if you intend to reduce its scope later. Anthropic's Dreams design starts with full user review of each consolidated store. That is operationally heavy, and most teams will eventually move to sampling or to automated regression checks. Start at full review anyway, because it forces you to look at what the consolidation produces in your specific domain, before you trust the process enough to run it without supervision.
What I Am Not Claiming
This is a working model, not a theorem. The three part framework (does consolidation happen, are the inputs safe, does the output match the user's intent) is one reasonable cut at the problem space. The boundaries between safety and quality blur in practice, and a more sophisticated model might collapse them or split them differently.
I am not arguing that Hermes is the wrong product. The community conversation around it is exactly what a healthy open source project looks like when it is working through hard problems. The maintainers' decision against the tiered proposal reflects design opinions I do not have full context on. The fact that a fix landed for the boundary violation report is evidence the team responds when concrete problems surface. By the time you read this, specific threads may be resolved or the design conversation may have moved on.
I am also not arguing that Anthropic's Dreams design solves the quality question. It gives the user the veto. The user still has to do the reviewing. If the user accepts a consolidated store without reading it carefully, the design protection does not help.
What I am arguing is that consolidation quality is the underdiscussed half of the agent memory conversation. The Memo paper made the case that current systems are not consolidating. The next question is what consolidation should look like, and the field is shipping divergent answers right now in real products. Anyone building an agent that learns from its own experience should make these decisions deliberately, before the first consolidation run, not after.
By the Numbers
Anthropic's Dreams consolidation feature (shipped May 2026) explicitly leaves the input memory store unmodified and gives the user veto over the consolidated output: "The input store is never modified, so you can review the output and discard it if you don't like the result."
Anthropic Engineering, Dreams in Claude Agents documentation, May 2026
NousResearch's Hermes Agent issue #25833 (opened May 14, 2026) argues that when the same model authors a skill from experience, runs the skill on future tasks, and judges whether it is working, the collapse of three roles into one model creates a structural blind spot the judge cannot detect.
NousResearch Hermes Agent issue tracker, #25833 (open as of writing)
Hermes Agent issue #17583 (opened April 29, 2026) proposed a two-tier skill system where user-locked skills would be protected from agent-driven updates; maintainers closed it as not planned, recording an explicit design choice against the tiered model.
NousResearch Hermes Agent issue tracker, #17583 (closed as not planned)
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.