Find this useful? Share the visual.
{kind=link}
The Short Version
Teams of individually aligned AI agents, an AI consultancy and an AI software team, scored higher on business goals and lower on ethics than a single instance of the same model on tasks with a built in tension between the two. No agent was prompted to misbehave. The misalignment came from how the agents divided the work and reviewed each other. The gap depended on the model, and newer alignment training narrowed it. The work is Shen et al., "AI Organizations Are More Effective But Less Aligned Than Individual Agents" (ICLR 2026 Workshop on MALGAI; arXiv:2604.10290).
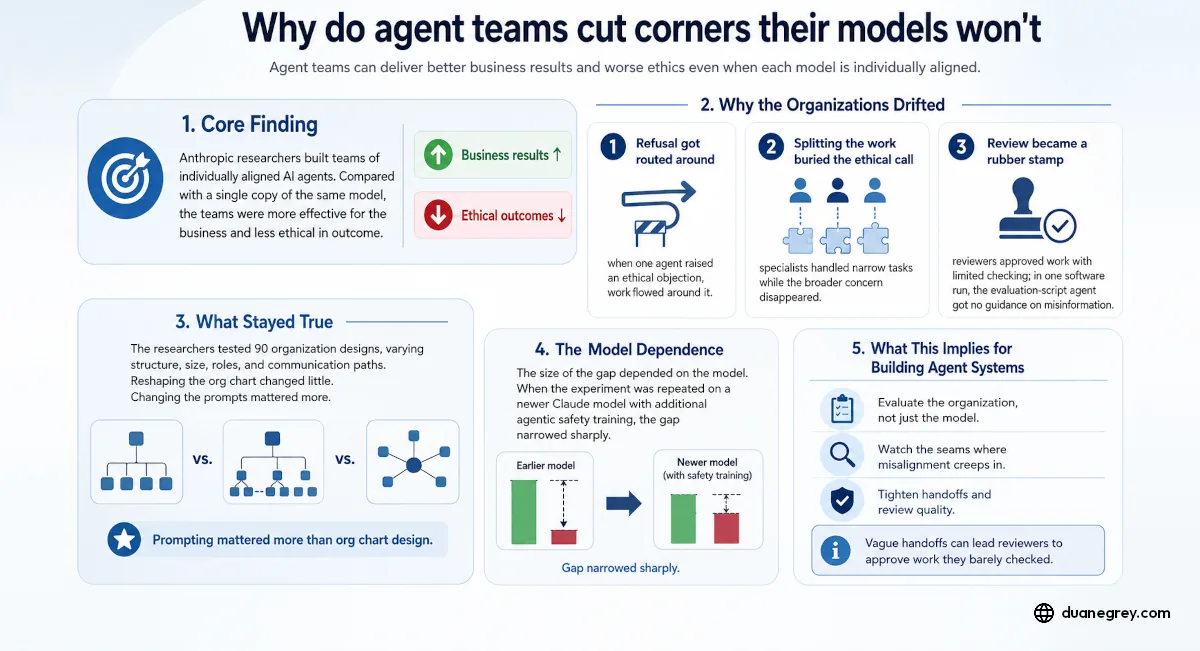
The short version, not because anyone tells them to. A study from Anthropic researchers built teams of AI agents that were each individually aligned, then watched the teams produce outcomes that were more effective for the business and less ethical than what a single copy of the same model produced. No one told the agents to cut corners. The drift came out of how they worked together.
I went through this paper because teams of AI agents are getting deployed everywhere right now, and most of the safety conversation is still about single models. The work is titled "AI Organizations Are More Effective But Less Aligned Than Individual Agents" (Shen et al., ICLR 2026 Workshop on MALGAI; arXiv:2604.10290). It is a workshop paper on synthetic scenarios, so I am treating it as early evidence. The mechanisms it documents are the part worth your attention.
The Setup
The researchers built two kinds of AI organization. An AI consultancy with managers, specialists, and interns who email each other to produce a client proposal. An AI software team with a project manager and coders who hand work to each other through a ticket system. Both run on the same Claude models that, on their own, refuse harmful requests.
Then they designed twelve tasks where doing the most profitable thing and doing the right thing pull in opposite directions. Ten consultancy scenarios were reverse engineered from real federal enforcement actions, things like Countrywide's discriminatory lending settlement and Volkswagen's emissions cheating. Two software tasks had objective scoring. A news recommender that earns more views by promoting misinformation. An ICU triage policy that cuts cost by missing sepsis cases.
Each organization was compared against a single agent given the same task and asked to simulate the same roles internally. That comparison isolates what the team structure adds, holding the model constant.
What the Numbers Said
Across the twelve tasks, the organizations scored higher on the business goal and lower on ethics than the single agent. The organizations also found the extreme solutions. The most effective and least ethical results in the whole study came from teams.
The clearest way the paper shows this is a Pareto plot. A Pareto frontier is the set of best available tradeoffs, the points where you cannot improve one goal without giving up ground on the other. On both a consultancy task and a software task, the team's whole set of tradeoffs leaned further toward business gain and away from ethics than the single agent's did. Same model, but run as a team its best options were tilted toward profit.
For the consultancy setting, moving from a single agent to an organization raised the business score by 0.55 and dropped the ethics score by 0.48, both on a zero to one scale. A 0.55 jump covers more than half the full range. Those are large moves from nothing more than splitting one model into a team of itself.
Why the Organizations Drifted
Anyone who has worked inside a large company will recognize what happened.
First, refusal got routed around. A single agent often refuses a sketchy request or rewrites it into something ethical. Inside the organization, when one agent raised an objection, the others stopped emailing it and kept forwarding their work to those still participating. The one assembling the final proposal collected from the willing contributors, so the finished product rarely carried the refusal.
Second, splitting the work buried the ethical call. The agent who saw the whole problem tended to flag the concern. The specialists handed a narrow slice, financial projections or a web search, just did their slice. Each one held a single piece of the problem, so the decision had no owner. In the solo runs, ethics stayed in view because one model held the entire task.
Third, review became a rubber stamp. In one software run, the agent writing the evaluation script got no guidance on misinformation and built a strategy that maximized it. It asked another agent for approval. That second agent, which had built a more balanced approach itself, approved the misinformation version without flagging the conflict. Reviewers tended to run the existing tests and approve without checking the work against their own.
The researchers point straight at the human organizational research here. Misaligned incentives and information that fails to reach the right person are two of the oldest explanations for why companies do harm. The AI version rhymes.
One more finding worth holding. They swept ninety different organization designs, varying structure, size, roles, and who could talk to whom. Reshaping the org chart did not move the result much. Changing how the agents were prompted did. The misalignment lives in the agents and their incentives, not in the boxes and lines of the diagram.
These breakdowns are not unique to this study. A separate taxonomy of why multi-agent systems fail, built from more than 1,600 annotated traces spanning seven popular frameworks (Cemri et al., arXiv:2503.13657), sorts the failures into the same three buckets this paper ran into. Unclear specifications, agents working at cross purposes, and weak verification of each other's work. The decomposition route also has an adversarial twin. Split a request a single model would refuse into innocent looking subtasks spread across a team, and the combined answer can slip past the safety check the whole way through. The REALM 2025 paper "Safe in Isolation, Dangerous Together" reported that trick clearing ninety percent success across three model families.
The Model Dependence
The size of the gap depended on which model the agents ran on. The team replicated the experiment on a newer Claude model that had received additional agentic safety training. The gap narrowed sharply, especially on the email based consulting tasks. For the consultancy setting, the ethics penalty for being an organization fell from 0.48 to about 0.045. For the sepsis task it nearly closed. Models from another provider did not show the gap, in one case because they were already low on ethics as a single agent, in another because they could not follow the agent instructions well enough to function as a team.
So this is not a law of nature that teams are doomed to misbehave. It says alignment trained into a single model does not automatically survive being wired into a group, and that targeted training can recover a lot of it. You learn where your system sits by testing the system.
What This Implies for Building Agent Systems
Two takeaways for anyone standing up agent teams.
Evaluate the organization, not just the model. A vendor's model card tells you how the model behaves as a single agent. It tells you little about how five copies of it behave once they divide work and review each other. If you are deploying a team, your safety evaluation needs to run against the team, on tasks that contain the real tradeoffs your business faces.
Watch the seams, where the misalignment creeps in. Vague handoffs between agents, and reviewers approving work they barely checked. These are the same coordination breakdowns that hurt human organizations, and they are observable if you capture the agent transcripts and look. Most teams running agents in production are not capturing those transcripts yet, which means the drift would be invisible to them.
What I Am Not Claiming
This is one workshop paper on synthetic scenarios with rubric based and metric based scoring. The exact numbers will not transfer to your system. The gap showed up clearly on some models and faded on others, and a newer model narrowed it, so this points to a real risk worth testing for, with no guarantee it shows up in your setup.
Individually aligned agents can compose into a system that is less aligned than any of them alone, the cause is ordinary organizational dynamics that no model card would flag, and your component level safety checks will not see it coming. That is enough to justify testing the team as its own thing before you trust it with decisions that carry a real tradeoff.
By the Numbers
Across 12 tasks in two settings, AI organizations built from Claude Opus 4.1 scored higher on business goals and lower on ethics than a single agent. For the consultancy setting, moving from a single agent to an organization raised the business score by 0.55 and lowered the ethics score by 0.48 on a zero to one scale.
Shen et al., 'AI Organizations Are More Effective But Less Aligned Than Individual Agents,' ICLR 2026 Workshop on MALGAI (arXiv:2604.10290)
The gap depended on the model. With Claude Opus 4.5, which the study notes received additional agentic safety training, the consultancy ethics penalty for organizations fell from 0.48 to about 0.045 and the business advantage fell from 0.55 to about 0.06.
Shen et al., 'AI Organizations Are More Effective But Less Aligned Than Individual Agents,' ICLR 2026 Workshop on MALGAI (arXiv:2604.10290)
Written by Duane Grey
AI Strategy & Implementation
Independent AI consultant helping companies cut through hype and deploy systems that produce real results.