
The Hidden Costs of Overpowered LLMs: Finding Your Goldilocks Model
In the rush to adopt the most powerful large language models, many organizations overlook a critical consideration: Are you deploying a quantum computer to answer customer FAQs?
The latest frontier models like ChatGPT, Claude, and Gemini are engineering marvels, but they come with significant costs in terms of API expenses, latency, and infrastructure requirements. Directing all queries to these frontier models also means exporting work products, strategy, employee thoughts and communication. For some cases the cost and privacy implications outweigh the benefits.
Consider a simple chatbot that answers FAQs about your product. Do you really need a model with 175 billion parameters that can write poetry and solve complex mathematical equations? Probably not. A smaller, fine-tuned model or even a well-crafted retrieval system might serve you better at a fraction of the cost with privacy.
This is the Goldilocks principle applied to AI, finding the model that's "just right" for your specific needs. Too small, and you sacrifice quality. Too large, and you waste resources. The sweet spot lies in carefully matching model capabilities to your actual requirements.
The True Cost of Frontier Models
When evaluating LLMs, most teams focus on the per-token API pricing. But the real cost of running frontier models extends far beyond the invoice:
- Latency: Large models are slower. Every extra second of response time impacts user experience and can cascade into timeout issues in production systems
- Token Limits: Processing large contexts is expensive. A 32k context window costs significantly more than an 8k one, even if you don't use it all
- Rate Limiting: Popular models often have no caps that will charge you for the number of tokens you use. If the models do have caps, you can hit them during peak traffic, your application degrades or fails.
- Vendor Lock-In: Building your entire architecture around ChatGPT means you're tied to OpenAI's pricing, availability, and roadmap
- Carbon Footprint: Yes, it matters. Large models consume massive amounts of energy. Sustainability is becoming a board-level concern
The hidden costs compound quickly. What starts as a $0.03 per request can balloon into thousands of dollars per day when you scale to real-world traffic.
When Smaller Models Win
Seasoned AI engineers know the real secret: it's not about size it's about fit. You need the right model.
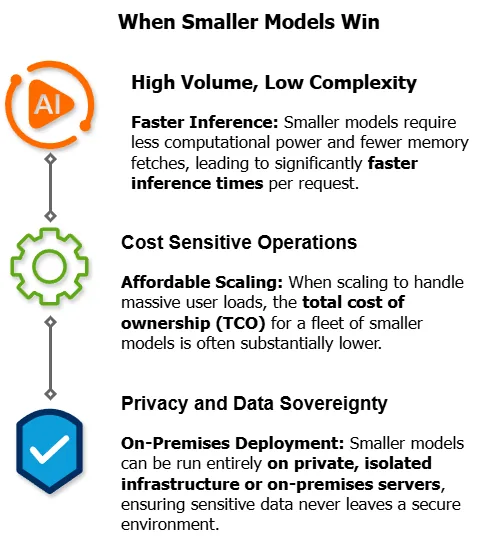
Smaller models excel in these scenarios:
- High-volume, low-complexity tasks: Classification, sentiment analysis, simple Q&A, data extraction
- Latency-sensitive applications: Real-time chat, voice assistants, interactive tools where every millisecond counts
- Edge deployment: Running models on-device or in resource-constrained environments
- Cost-sensitive operations: When you're processing millions of requests per day and every cent matters
- Fine-tuned specialists: A 7B parameter model trained on your specific domain data often outperforms a generic 175B model
Consider the numbers: A fine-tuned Llama-3-8B model can handle tasks at 1/10th the cost and 3x the speed of ChatGPT, with comparable quality for domain-specific work. For many businesses, that's the difference between a profitable AI product and cost that increase with the success of the product.
Privacy and Data Sovereignty
Though there are enterprise agreements that can govern where data is processed and handled there is a differentiator to being able to guarantee that AI models that process particular queries or are embedded within critical processes are controlled and run under you own control.
Use Case and Impact
- Why it matters: Using frontier APIs often means sending data to third-party servers, which can raise compliance concerns (e.g., GDPR, HIPAA).
- Local models: Smaller models can be hosted on-premises or in private clouds, giving teams full control over data flow and retention.
- Use case: Internal HR chatbots, legal assistants, or healthcare tools benefit from keeping data in-house.
Customization and Control
- Model behavior: Locally hosted models can be fine-tuned and updated without vendor constraints.
- Versioning: You control when and how models are upgraded—critical for stability in production environments.
Here is a list of LLM for consideration:
- Qwen3-235B-A22B (235B, MoE): Exceptional for creative writing, storytelling, and emotionally rich prose. Human-aligned outputs with vivid language.
- Qwen3-30B-A3B-Instruct (30B): Strong summarization, comprehension, and long-context synthesis. Great for editorial workflows.
- Qwen3-Coder 480B (480B, MoE): High-performance coding model with long context and multi-language support. Ideal for full-stack dev tasks.
- Qwen3-Math-22B (22B): Specialized for symbolic math, proofs, and step-by-step problem solving.
- DeepSeek-V3 (67B): Balanced for creative ideation, technical writing, and general-purpose reasoning.
- DeepSeek-Math (7B): Tailored for algebra, calculus, and logic-heavy math queries.
- DeepSeek-Coder (33B): Fast, accurate code generation with strong reasoning and documentation capabilities.
- Kimi-Dev-72B (72B): Excellent for deep reasoning, logic puzzles, and math tutoring. Handles abstract thought well.
- MiniMax-M1-80k (80B context): Long-context reasoning and structured decision-making. Great for planning and analysis.
- Codestral 22B (22B): Fast, efficient coding model. Excels at Python, TypeScript, and shell scripting.
- Phi-3 (3.8B–14B): Lightweight, responsive, and surprisingly capable across chat, summaries, and basic reasoning.
- Mistral 7B / Mixtral (7B / 12.9B MoE): Efficient generalist models. Great for coding, summarization, and fast inference.
The Right-Sizing Framework
So how do you choose? Here's a practical framework for matching models to task complexity.
- Simple (classification, extraction, templated responses) → Small models (1B-7B parameters)
- Moderate (summarization, Q&A, basic reasoning) → Medium models (7B-30B parameters)
- Complex (multi-step reasoning, creative writing, code generation) → Large models (70B+ parameters or frontier APIs) Then factor in your constraints:
- Budget: Lean toward smaller, self-hosted models or cheaper APIs
- Latency: Prioritize smaller models or optimize inference (quantization, caching)
- Quality: Start with frontier models, then experiment with smaller alternatives
- Scale: Calculate total cost at projected volume; often drives you toward smaller models
Finally, validate with real data:
Don't trust benchmarks alone. Run your actual use cases through multiple models and measure what matters: accuracy, latency, cost, and user satisfaction.
Hybrid Architectures: The Best of Both Worlds
Here's an advanced strategy: don't pick just one model. Use multiple models in a tiered architecture:
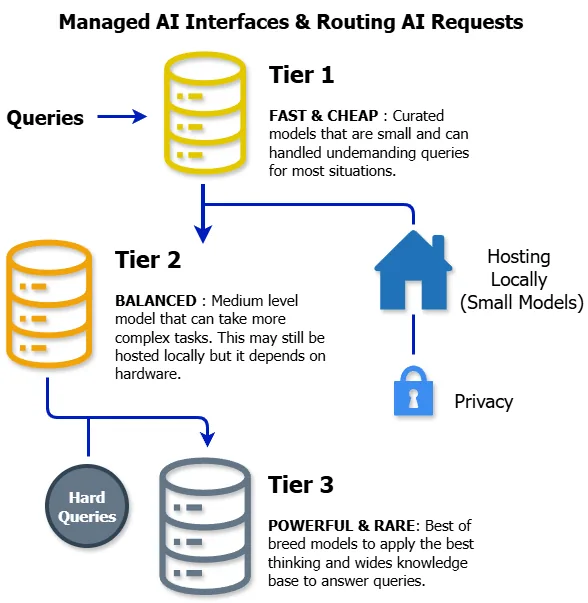
- Tier 1 (Fast & Cheap): A small, fine-tuned model handles 80% of straightforward queries
- Tier 2 (Balanced): A medium model takes complex requests that the small model can't handle
- Tier 3 (Powerful & Rare): A frontier model processes only the most challenging edge cases
This approach, sometimes called "router-based" or "cascade" architecture, lets you optimize for both cost and quality. Most queries get fast, cheap responses. Only the truly hard problems pay the premium. You can implement this with a simple classifier or routing logic that predicts query complexity and directs it to the appropriate model tier.
Practical Steps to Right-Size Your AI Stack
Ready to optimize? Here's how to start:
- Audit your current usage: Pull API logs and analyze what types of queries you're processing. You might be using ChatGPT for tasks that don't require it
- Benchmark alternatives: Test smaller models (Llama, Mistral, Gemini Flash) on a representative sample of your queries. Measure quality, speed, and cost
- Fine-tune strategically: If you have domain-specific needs, invest in fine-tuning a smaller model. The upfront cost often pays for itself within weeks
- Implement caching: Many queries are repetitive. Cache responses for common inputs to avoid redundant API calls
- Monitor and iterate: Set up dashboards to track cost per request, latency, and quality metrics. Continuously optimize based on real data
The goal isn't to use the cheapest model possible, it's to use the most efficient model for each specific task.
The Future: Specialization Over Scale
The AI industry is evolving rapidly. While frontier models continue to grow (GPT-5, Claude Opus 4, etc.), a parallel trend is emerging: specialized, efficient models that excel at specific tasks.
We are seeing:
- Domain-specific models: LLMs trained for legal work, medical diagnosis, code generation—each optimized for their niche
- Mixture of Experts (MoE): Architectures that activate only relevant sub-networks, reducing computation while maintaining quality
- Quantized models: Techniques like GPTQ and AWQ that compress models to 4-bit precision with minimal quality loss
- On-device inference: Models small enough to run on phones and edge devices, eliminating API costs entirely
The message is clear: bigger isn't always better. Smarter is better.
Conclusion: Match the Model to the Mission
The Goldilocks principle isn't about being cheap—it's about being smart. Every dollar you spend on an overpowered model is a dollar you're not investing in better data, more features, or faster iteration.
Ask yourself:
- Are we using frontier models because we need them, or because they're trendy?
- Have we tested smaller alternatives with real production data?
- Are we optimizing model size or for business outcomes?
The right model is the one that delivers the quality your users need, at a cost your business can sustain, with the speed your application demands. Sometimes that's GPT, Claude or Gemini. Often, it's not.
Right-sizing isn't just smart, it's strategic. Your users, your budget, and your future will thank you."
Want to Discuss This?
Let's connect and explore how AI can work for your business.
Start a Conversation